Stable Diffusion, however, has its own trick to deal with high-dimensionality. Instead of working with images, its autoencoder element turns them into low-dimension representations. There’s still noise, timesteps, and prompts, but all the U-Net’s processing is done in a compressed latent space. Afterward, a decoder expands the representation back into a picture of the needed size.
Video-generation models
The video models build upon the concepts introduced in image diffusion. This is perhaps the most evident in MetaAI’s Make-a-Video. The general idea is to take a trained diffusion model, which already knows how to associate text with video, and equip it with a set of video processing tools. The training here can be performed on unlabeled data. The algorithm can eat random videos from the web and learn realistic motion. The components of the network include:
- A base DALL-E-like diffusion model with a U-Net architecture that generates 64×64 images from random noise. It has a CLIP encoder, embedding prompts into a multi-modal visual-language space, and a prior network that encodes the information into an image vector. This way, the model gets a visual representation of text, which it uses as guidance to generate relevant images. The two upscaling networks in the end produce higher-resolution images.
- Extra layers to handle sequential data and temporal dimensions. Besides the standard 2d, each layer gets an additional 1d convolution that ties the frames together. At the same time, each spatial attention layer is also enhanced with an extra one, serving as a bridge to temporal dimensions. While the weights and biases for 2d convolutions remain unmodified, the 1d convolutions must be trained from scratch.
- An interpolation network that increases the frame rate. The network can estimate masked frames, so it’s used to generate data objects that enhance temporal coherence.
- Two spacial super-resolution models (SSMs) that gradually improve image resolutions in each frame.
The Make-a-Video network training is highly complicated since different network elements are trained on different data. The prior and spatial super-resolution components are trained exclusively on pictures. The text-to-image diffusion model utilizes text-image data pairs, and the added video-specific convolution and attention layers are shown unlabeled videos.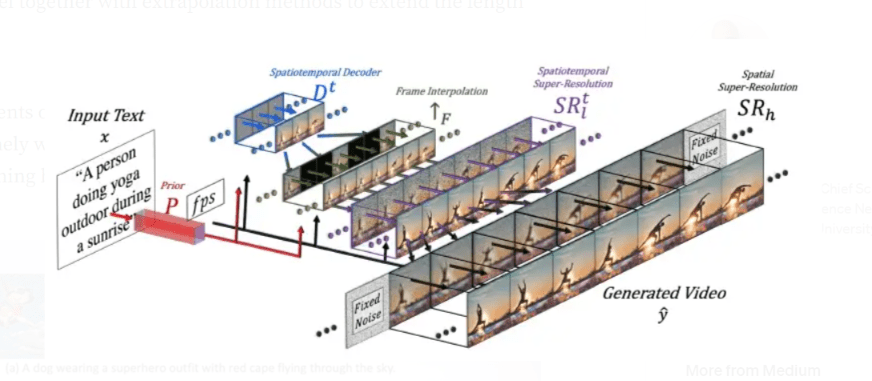 Figure 3. Make-a-video architecture
Figure 3. Make-a-video architecture
How does Imagen differ from Make-a-Video?
The architectural differences between these two major models are not significant. In Imagen, the CLIP encoder and prior network are replaced with the T5-XXL transformer, which is trained on text only, unlike CLIP. The base diffusion model is also enhanced with additional convolution and attention layers, but its training is slightly different as it is shown both image and video data simultaneously, and the model treats images as single-frame videos. This means video descriptions, which are hard to come by on the web, must also have been used and they’ve probably come from some internal Google-generated dataset. Next, we again have the supersampling network to get a higher framerate and the two SSR models. But then, Imagen goes further by adding two more upsampling models and yet another SSR.
Stable Diffusion applications
Diffusion models produce more crisp and stable outputs than GANs. They could therefore replace adversarial networks in any task where the generation of realistic synthetic data is required.
3D modeling. Google’s DreamFusion and NVIDIA’s Magic3D create high-resolution 3D meshes with colored textures from text prompts. With unique image conditioning and prompt-based editing capabilities, they can be used in video game design and CGI art creation (helping designers visualize, test, and develop concepts quicker), as well as manufacturing.
Image processing. The applications here include super-resolution, image modification/enhancement, synthetic object generation, attribute manipulation, and component transformation.
Healthcare. The models can help reduce the time and cost of early diagnosis while increasing its speed. In addition, they can significantly augment existing datasets by performing guided image synthesis, image-to-image translation, and upscaling.
Biology. Stable Diffusion can assist biologists in identifying and creating novel and valuable protein sequences optimized for specific properties. The networks’ properties also make them great for biological data imaging, specifically for high-resolution cell microscopy imaging and morphological profiling.
Remote sensing. SD can generate high-quality and high-resolution sensing, and satellite images. The networks’ ability to consistently output stable multispectral satellite images might have huge implications for remote sensing image creation, super-resolution, pan-sharpening, haze and cloud removal, and image restoration.
Marketing. Stable Diffusion networks can create novel designs for promotional materials, logos, and content illustrations. These networks can quickly produce high-resolution and photo-realistic images that meet specific design requirements, and output a wide range of shapes, colors, sizes, and styles. In addition, the algorithms enable augmenting, resizing, and upscaling existing materials, so they can potentially improve the effectiveness of marketing campaigns.
Summing up
Diffusion models are insanely popular right now. Their unique image-formation process, consisting of the sequential application of denoising autoencoders, achieves stable state-of-the-art synthetic results on images and other data types. Stable Diffusion, which takes image processing out of the pixel space and moves it into the reduced latent space, enables us to achieve high-quality results while running the networks on our laptops. And, the latest text-to-video networks extend pre-trained SD networks with advanced video processing capabilities.
Although the models are new, there are already many companies that have figured out how to use them to their advantage. If you would like to learn how diffusion networks can benefit your organization, contact our experts now.


 We created this image using Stable Diffusion
We created this image using Stable Diffusion Figure 1. Realistic face generated by StyleGAN2
Figure 1. Realistic face generated by StyleGAN2 Figure 2.
Figure 2. 






