 Figure 2. Monocular vision vs. stereo vision
Figure 2. Monocular vision vs. stereo vision
The triangulation principle uses the relationship between the distance to the object, the baseline (distance between the cameras), the disparity (the difference in the horizontal position of the object in the left and right images), and the focal length (the distance between the camera length and the image sensor).
The disparity is calculated after an algorithm finds the features (edges, corners, etc.) that can be matched between the two images so as to determine corresponding points, and then the horizontal distance between them is measured. Finally, the depth is computed with a formula:
depth = (baseline * focal length) / disparity
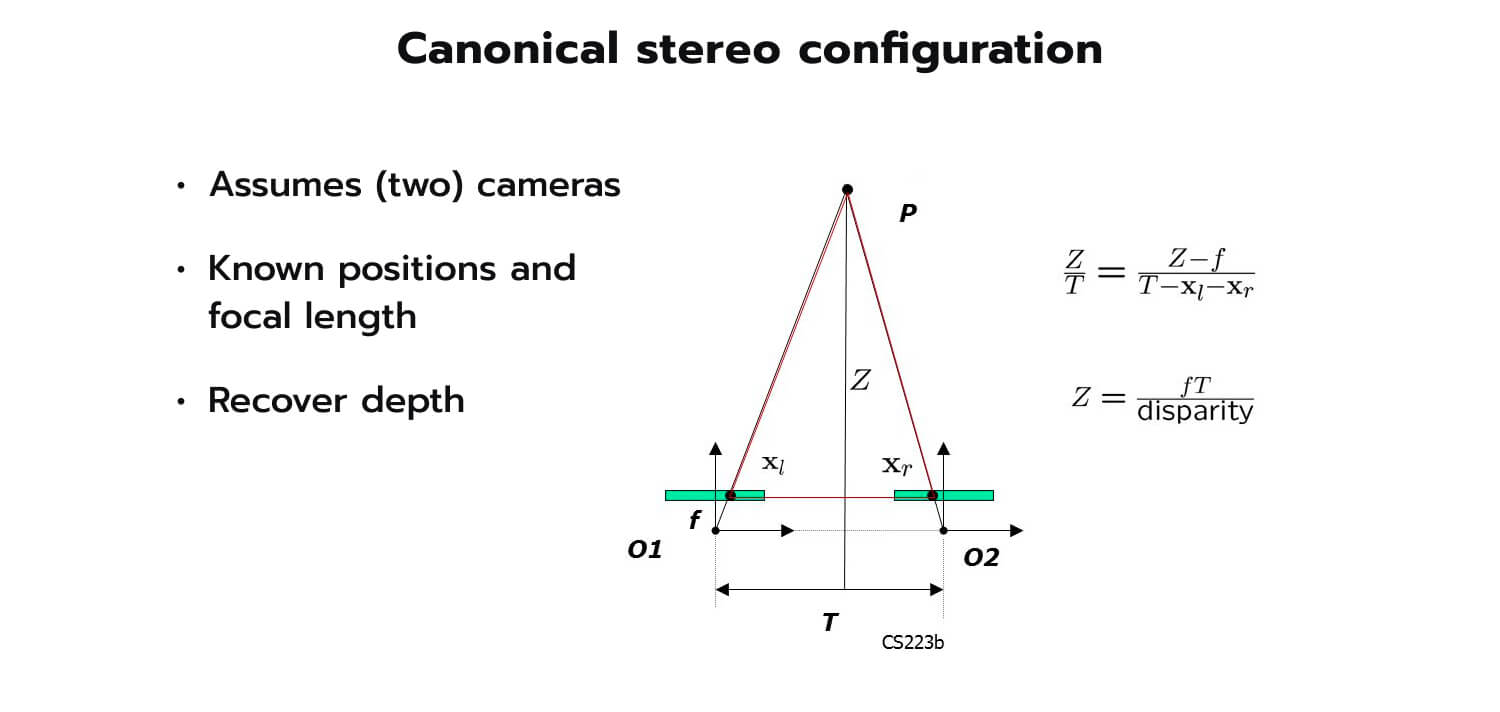 Figure 3. Canonical stereo configuration
Figure 3. Canonical stereo configuration
As shown in Figure 3, the larger the disparity, the smaller the depth, and vice versa. In other words, the larger the disparity, the closer the object is to the cameras.
Modern stereo vision systems, which are essentially implementations of the triangulation principle, calculate depth information in a nuanced way using sophisticated computer vision methods. These algorithms typically have four stages: matching cost computation, cost aggregation, disparity optimization and selection, and disparity refinement. All of these phases are aimed at creating and tuning disparity maps that show the differences between corresponding pixels in images which ultimately enable the recovery of the 3D structure within the scene.
- Matching cost computation: The similarity between corresponding pixels in the left and right images (called matching costs) is computed. This is usually done by comparing gradients, intensity or color values, and other image features.
- Cost aggregation: The matching costs for each pixel are combined with the costs of neighboring pixels. The noise and inconsistencies are then reduced, enabling the creation of accurate disparity maps.
- Disparity optimization and selection: This is the search for the best matching disparity value for each pixel, given the aggregated matching costs. Various optimization techniques can be used here. This step results in the algorithm selecting the optimal disparity value for each pixel based on certain criteria, such as the smoothness of the disparity map.
- Disparity refinement: The refinement of the disparity map involves post-processing techniques such as sub-pixel interpolation, edge-preserving filtering, or occlusion handling. This further removes uncertainty and noise in the disparity map, and helps elevate the accuracy and robustness of the stereo vision system, especially in challenging environments or with complex scenes.
Another important thing we must mention here is the cost volume, a data structure that facilitates the computation of matching costs between the pixels in different images. Basically, it is a grid or a tensor that stores the matching cost values of pixels in two images. It can also be thought of as a 3D matrix, where the dimensions correspond to coordinates (height and width) and the disparity range. Each element represents the matching cost between a pixel in one image and a candidate pixel in the other image at a specific disparity level.
Concise and informative representation is crucial in stereo matching. At Avenga, we have been successfully using the Attention Concatenation Volume (ACV) method to achieve elevated stereo vision accuracy. This method relies on attention mechanisms to enhance information aggregation across multiple image scales. It suppresses redundant information while highlighting the matching-related data. Incorporating ACV into a stereo-matching network has allowed us to achieve better performance while utilizing a far more lightweight aggregation network. Moreover, by slightly tweaking the ACV to produce disparity hypotheses and attention weights from low-resolution correlation clues, we can achieve real-time performance in obstacle detection. This way, the network can attain similar levels of accuracy at a significantly reduced memory and computational cost.
Final words
As our indoor experiments have proved, stereo cameras do have distinct advantages over LiDARs, which still are powerful sensors with their own strengths. This includes their ability to capture rich visual information such as color, texture, and object shape, which can provide important cues for object detection, segmentation, and recognition.
Additionally, stereo cameras also offer a higher spatial resolution and a wider field of view than LiDARs, which can contribute to the generation of more detailed and comprehensive scene information. Stereo cameras can capture high-resolution images with pixel-level accuracy, making them especially useful for detecting small or thin objects such as wires, poles, or signs.
Unlike LiDARs, stereo cameras are robust to occlusions and other obstacles such as rain, fog, or dust. LiDARs lasers can be blocked or scattered by objects in the environment, and this might result in incomplete or noisy depth maps. In contrast, stereo cameras can use texture or color information to infer the depth of occluded or partially visible objects. They can compensate for visual artifacts using advanced algorithms such as multi-view stereo.
Finally, stereo cameras are generally less expensive and consume less power than LiDARs, making them a more cost-effective option for cost-sensitive or resource-constrained applications.
If you’d like to get more in-depth insights into the utilization of stereo cameras and other innovative technological approaches for precise obstacle detection, contact us right now and promptly get in touch with one of our esteemed experts. They are well-equipped to provide you with comprehensive information and assistance.


 Figure 1.
Figure 1. 






