

End of Support for Microsoft Products: What You Need to Know
Stay informed about the end of support for Microsoft Office 2016 & 2019, Exchange Server 2016 & 2019, and Windows 10.

We picked sentiment analysis as the most critical measurement of users’ opinions and compared the results from Cloud Google Natural Language processing API, and the Avenga sentiment analysis algorithm built from the ground up by our data science team.
In the data-driven world, success for a company’s strategic vision means taking full advantage of incorporated data analytics and using it to make better, faster decisions. There is a vast amount of generated information in every business, 2.5 quintillion bytes a day, which is why organizations often apply Google natural language processing algorithms to interpret and clarify data for more accurate conclusions.
2.5 quintillion bytes of data are generated every day
What exactly does Google natural language processing technology solve? For one thing, it is a mechanism which helps computers analyze natural human language and produce accurate measurable results. It can be used to extract information from huge amounts of text in order to perform a much quicker analysis, which in turn helps businesses identify and understand new opportunities or business strategies.
Language processing is also a powerful instrument to analyze and understand sentiments expressed on line or through social media conversations regarding a product or service. Sentiment analysis can provide tangible help for organizations seeking to reduce their workload and improve efficiency.
→ Read more about Business Intelligence and Data Visualization
We picked sentiment analysis as the most critical measurement of users’ opinions and compared the results from Cloud Natural Language API by Google, and the Avenga sentiment analysis algorithm built from the ground up by our data science team.
Google Natural Language processing API is a pre-trained machine learning API that gives developers access to human-computer interaction, Google sentiment analysis, entity recognition, and syntax analysis. Google Cloud Natural Language sentiment analysis is a kind of black box where you simply call an API and get a predicted value. It is a floating point value between -1 and 1 indicating whether or not the entire text string is positive which translates to sentiments.
Let us guess the effort Google made by analyzing a typical sentiment analysis pipeline through application of supervised machine learning techniques:
Our aim was to find out what accuracy improvements can be achieved in understanding sentiments in the case of a custom client problem if we implement all the above steps by ourselves and provide all possible fine tuning at each step.
What if we must analyze product review sentiment only? Let us build the model that is specifically trained on product reviews and see if it is worth the effort. The script for the following analysis can be found on GitHub.
On the first step in our case, we took some sample labelled reviews to determine positivity versus negativity. Our dataset came from IMDB and contained 50,000 highly polarized movie reviews for binary sentiment classification. The final model was built on a training data set of 25,000 reviews, which were perfectly balanced between half negative and half positive samples. The rest of the reviews were used to test the model and confirm accuracy.
Let’s take a first glance at the data we collected, using a word cloud: After collection, the data had to be cleaned, which included conversion of the data to lowercase, punctuation removal, and tokenizing the documents. We also pruned the text by removing stop words, e.g., ‘a’, ‘the’, ‘in’, etc., and both common and unusual terms. This significantly improved the model’s accuracy and training time. Note that all data manipulation performed on the IMDB training set must be applied to the test set afterwards.
After collection, the data had to be cleaned, which included conversion of the data to lowercase, punctuation removal, and tokenizing the documents. We also pruned the text by removing stop words, e.g., ‘a’, ‘the’, ‘in’, etc., and both common and unusual terms. This significantly improved the model’s accuracy and training time. Note that all data manipulation performed on the IMDB training set must be applied to the test set afterwards.
At the 3rd step, we represented documents in a vector space. Such representation of text documents is a challenging task in machine learning. There are not many good techniques to do this. For instance, the well known but simplistic method of “bag of words” loses many subtleties of a possible good representation, e.g., word order. We used the “word2vec” technique created by a team of researchers led by Tomas Mikolov. Word2vec takes as its input large amounts of text and produces a vector space with each unique term, e.g., word or n-gram, being assigned a corresponding vector in the space. Word vectors are positioned in the vector space such that words sharing common contexts are located in close proximity to one another in the space.
To improve the model even more, we used n-grams instead of words (up to 2-grams) and marked each with a unique id, built a vocabulary and constructed a document-term matrix.
→ Read more about Data Protection vs Data Privacy vs Data Ethics
Our goal is to predict discrete outcomes in our data showing whether or not a movie review is positive or negative. Predicting such outcomes lends itself to a type of Supervised Machine Learning known as Binary Classification. One of the most common methods to solve for Binary Classification is Logistic Regression. The goal of Logistic Regression is to evaluate the probability of a discrete outcome occurring based on a set of past inputs and outcomes. In our case we fitted the Logistic Regression model with an L1 penalty and 5 fold cross-validation. The L1 penalty works like a feature selector that picks out the most important coefficients, i.e., those that are most predictive. The objective of Lasso regularization (L1 penalty) is to balance accuracy and simplicity. This means we pick a model with the smallest number of coefficients that also gives a good accuracy.
Here is a plot of area under the ROC curve as a function of lambda, where lambda is a free parameter-near penalty term, added to the log likelihood function. Lambda is usually selected in such a way that the resulting model minimizes sample error. The plot shows that the log of the optimal value of lambda, i.e., the one that maximises AUC, is approximately -6, where we have 3,400 coefficients and the AUC equals 0.96.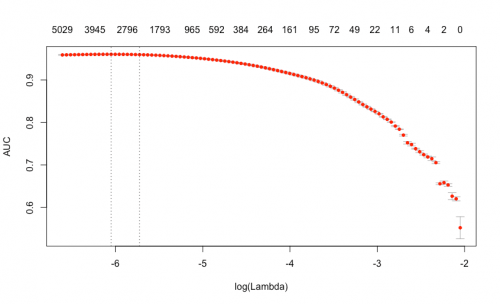 We have successfully fitted a model to our DTM. Now we can check the model’s performance on IMDB’s review test data and compare it to Google’s. However, in order to compare our custom approach to the Google NL approach, we should bring the results of both algorithms to one scale. Google returns a predicted value in a range [-1;1] where values in the interval [-1;-0,25] are considered to be negative, [-0.25;0.25] – neutral, [0.25;1] – positive.
We have successfully fitted a model to our DTM. Now we can check the model’s performance on IMDB’s review test data and compare it to Google’s. However, in order to compare our custom approach to the Google NL approach, we should bring the results of both algorithms to one scale. Google returns a predicted value in a range [-1;1] where values in the interval [-1;-0,25] are considered to be negative, [-0.25;0.25] – neutral, [0.25;1] – positive.
Let’s see an example of how Google evaluates the sentiment of the text. Here is the sample of the data we gathered:
“Simply one of the best movies ever. If you won’t get it – sorry for you. I believe that someday people will include this one in their all-time top 10’s. Not now, but in the far future.”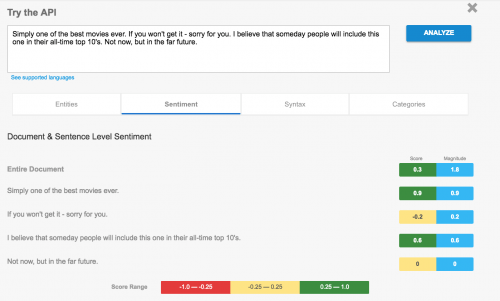 The overall sentiment of the document as judged by Google is positive, the score equals 0.3.
The overall sentiment of the document as judged by Google is positive, the score equals 0.3.
We built a model that predicts the probability of a review being positive or negative, i.e., returns a value in a range [0,1]. To make division of the interval [0,1] balanced with Google’s, we’ll consider everything less than 0.375 to be negative and everything greater than 0.625 to be positive, values in the middle define neutral class.
Here is the comparison of the custom model trained on the IMDB dataset vs Google performance.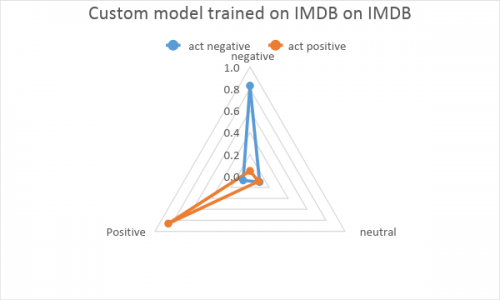 Custom model shows good accuracy except for a few errors visible on the center of graph, where some positive results are interpreted as negative and vice versa. The small neutral shift shows that model is well tuned.
Custom model shows good accuracy except for a few errors visible on the center of graph, where some positive results are interpreted as negative and vice versa. The small neutral shift shows that model is well tuned.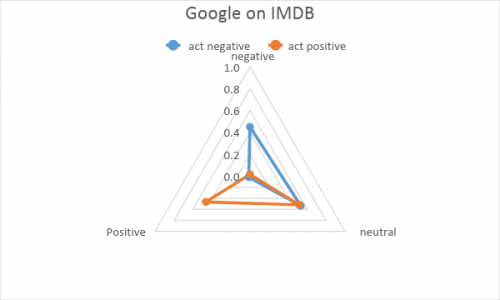 Separation of positive and negative results is even better in Google model, but there is a huge number of results interpreted as neutral. As the service is a universal product for the specific use cases, it is recommended that there should be some testing and adjustment of the threshold for “clearly positive” and “clearly negative” sentiments. That is a picture of what happens when we skip the step of tuning the interpreting approach. Next time we will definitely fix this, but for now let’s look at what happens when the model meets uncomfortable data.
Separation of positive and negative results is even better in Google model, but there is a huge number of results interpreted as neutral. As the service is a universal product for the specific use cases, it is recommended that there should be some testing and adjustment of the threshold for “clearly positive” and “clearly negative” sentiments. That is a picture of what happens when we skip the step of tuning the interpreting approach. Next time we will definitely fix this, but for now let’s look at what happens when the model meets uncomfortable data.
As a validation dataset, we collected more than 6,000 labelled reviews on Amazon Kindle and tested the model on them. Each review was scored by reviewers on a scale from 1 to 5. Here is a distribution of these scores: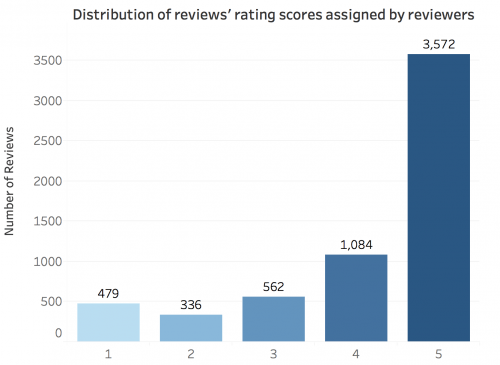 As you can see, the distribution is strongly left-skewed with a distinct peak at the highest value. It is interesting to see the comparison of results for custom vs. Google models on such unbalanced data. To deal with five actual review rating scores, we split them into three classes: negative (1, 2), neutral (3) and positive (4, 5). The predicted values of the custom and Google models were split into three classes just the way we did it for IMDB dataset.
As you can see, the distribution is strongly left-skewed with a distinct peak at the highest value. It is interesting to see the comparison of results for custom vs. Google models on such unbalanced data. To deal with five actual review rating scores, we split them into three classes: negative (1, 2), neutral (3) and positive (4, 5). The predicted values of the custom and Google models were split into three classes just the way we did it for IMDB dataset.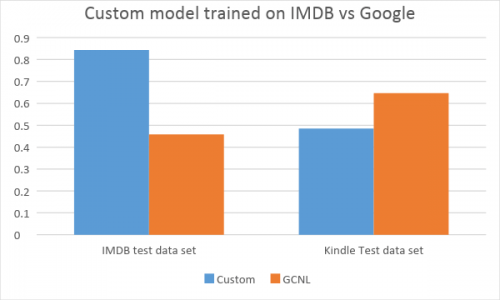 Custom model which was trained on IMDB showed significantly better results on IMDB, while Google simply failed this task. Thus, our approach performs very well in the domain on which it was trained. However, on a Kindle dataset, Google outmatches the custom model.
Custom model which was trained on IMDB showed significantly better results on IMDB, while Google simply failed this task. Thus, our approach performs very well in the domain on which it was trained. However, on a Kindle dataset, Google outmatches the custom model.
Can we improve the accuracy by training the custom model on the Kindle dataset? Let’s see the comparison of the Kindle trained custom model with Google on the Kindle dataset.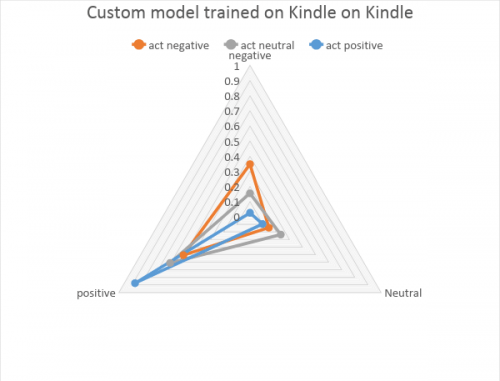 The custom model showed a clearly visible trend to classify both negative and neutral reviews as positive, which is not good and will show really bad results for negative reviews.
The custom model showed a clearly visible trend to classify both negative and neutral reviews as positive, which is not good and will show really bad results for negative reviews.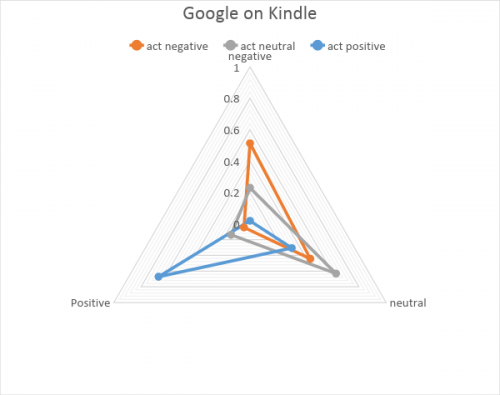 Google showed reasonably good negative and positive review separation, as well as room to play with neutral results interpretation.
Google showed reasonably good negative and positive review separation, as well as room to play with neutral results interpretation.
See what happens when custom Kindle trained data meets IMDB data.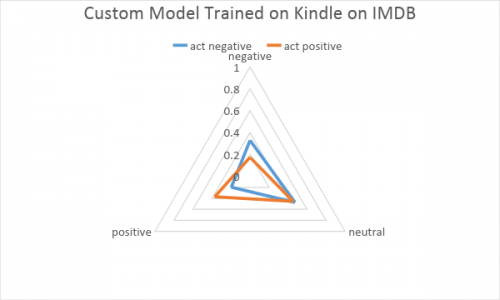 Additionally, a lot of reviews went to the neutral sack showing a bad situation in terms of positive-negative separation.
Additionally, a lot of reviews went to the neutral sack showing a bad situation in terms of positive-negative separation.
→ Read more about Data science perspective on Covid-19: a real life example

There are many ways to do sentiment analysis, but what Google offers is a kind of black box where you simply call an API and receive a predicted value. One of the advantages of such an approach is that there is no longer a need to be a statistician, and we have no need to accumulate the vast amounts of data required for this kind of analysis. Google NL also has the benefit of supporting all their features in a list of languages, as well as having a bit more granularity in their score (magnitude). The magnitude of a document’s sentiment indicates how much emotional content is present within the document. However, it is difficult to treat it correctly as its range is [0;+inf).
The obvious disadvantage is a lack of ability to fine tune the algorithm. The only possible tuning is an adjustment of the threshold for “clearly positive” and “clearly negative” sentiments for the specific use cases. Besides, usage costs for the Google Natural Language processing API are computed monthly based on which feature of the API is used, and how many text records are evaluated using those features.
In business, efficiency and profitability go hand in hand. No two businesses are the same, which is why so many prefer not to use off the shelf algorithms, but go for a more custom approach.

Stay informed about the end of support for Microsoft Office 2016 & 2019, Exchange Server 2016 & 2019, and Windows 10.
Ready to innovate your business?
We are! Let’s kick-off our journey to success!






