


End of Support for Microsoft Products: What You Need to Know
Stay informed about the end of support for Microsoft Office 2016 & 2019, Exchange Server 2016 & 2019, and Windows 10.

When we think about Artificial Intelligence (AI) processing natural language as a text we usually think of automatic translations, grammar and spelling checking, as well as chatbots.
However, the current generation of AI techniques excels at classification problems, including processing tons of documents to find information, determining relationships between them, and creating automatic tags that will help end-users or other systems traverse the document’s library using various angles for different purposes.
→ Read about Avenga’s sentiment analysis algorithm built from the ground up by our AI team
AI is already helping to analyze invoices and scientific research libraries which assists lawyers, doctors, and authors.
And, let’s not forget about search engines, both globally available on the internet and locally within enterprises.
Despite their known successes in the NLP area, AI scientists are constantly looking for better solutions to understand the meaning, context, and intent of sentences as well as things such as irony, jokes, and complex parallels.
→ Discover the key NLP tasks
Our case today does not require futuristic technology. It represents a very good application of current technologies for the benefit of a business in any domain, because all enterprises deal with documents, their storage, and even more importantly, searching and lexical analysis.
Lyubomyr Senyuk, Director of R&D at Avenga, explains what tagging is all about and what were the goals of the project that we are highlighting today.
Autotagging – what is it? Just AI proposing a few summary words for later reference, by you or other users?
Let’s start with the client’s problem and later we’ll try to see what’s available in terms of problems, terminology, and solutions.
An analyst writes analytical notes and adds some words to indicate what the note is about and to simplify a further search through the notes. This case seems simple and the natural desire is to immediately use some cutting-edge NLP library that allows AI to propose ‘hashtags’ for the user (what literally the client proposes).
At first glimpse, the environment of the problem looks similar to what is called social bookmarking: an action of connecting a relevant user-defined keyword to a document, image, or video, which helps the user to better organize and share their collection of interesting content.
A typical social bookmarking example is the #Hashtag mechanism on Twitter. Hashtags for Twitter were invented in 2007 by Cris Messina who proposed to use the crosshatch sign with text keywords to allow followers to filter content. The idea was widely accepted by the community and in several services, quickly creating a huge amount of tagged content. Such a significant amount of labeled data meant the easy use of data science, and many solutions emerged in the area of autotagging.
Unfortunately, we don’t have thousands of users constantly tagging documents and supporting the tag evolution, for example, as people on Twitter do. Instead, our users utilize industry-standard terminology, which gives us the opportunity to use some existing corpora of data and apply NLP techniques like topic modeling and named entity recognition to extract relevant entities.
One of the interesting cases a client raised is identifying new topic analysis that describes something (i.e., Covid 19 when it appeared), which requires nontrivial data science techniques like dynamic topic modeling.
→ Read how the topic modelling NLP technique helps to identify general topics from Wikipedia, such as Medicine, Politics, Finance, History, Law, etc., in any previously unseen text.
Stakeholders also noted that it would be good for the system to guide users through the tags, specifying in a similar manner to taxonomies work; when more general tags are entered it results in a more specific list and vice versa. Such exercises require more sophisticated approaches, like hierarchical clustering and topic modeling.
Additionally, general keywords like ‘agriculture’, ‘real estate’, and ‘bitcoin’ cause analysts to use entities as Company names, Geographical names, and enterprise specific keywords, like investment product names and other specific tags. This task requires solutions from the Named Entity Extraction domain.
As we can see, the problem is pretty broad and our implementation covers the most important parts of it.

Wherever you go (online), such as to a conference by a cloud vendor, you will see and hear that it’s not worth learning all these complex concepts or technologies. Turn-key solutions are out there and all you have to do is select the service and connect your data, and then it works.
All major cloud vendors (Amazon, Microsoft, Google, IBM, etc.) add new AI services on a regular basis, and in their words to make it “simpler”, to “democratize AI”, and to let “beginners” benefit from the power of AI technologies so as to lower that entry barrier.
→ Check out a comparison of cloud service providers: market share, cloud offerings, cost and price, locations, strength, weaknesses, and benefits.
The other factor, as always, is the low availability of true data scientists with a deep understanding of the underlying mathematical foundations and the lower level technologies and tooling.
So it seems to be very tempting to think that you shouldn’t reinvent the wheel but just use what is out there, learn how to use it well and customize it for your particular case; and that’s it. Yet, all of us in the IT services world have heard about these situations so many times, haven’t we?
But let’s analyze a very good example: the project we have completed successfully for one of our clients in the US market.
Olena Domanska, a Ph.D. in Mathematics and Mechanics and an expert in Data Science, Artificial Intelligence, Machine Learning and Deep Learning, answers some questions.
The goal was to tag documents with labels to enable a search through raw unstructured text quickly, process it, and get actual insights from the data across the notes in order to understand their (potential) customers, and identify market trends and risks for further informed business decisions.
We used Named Entity Recognition (NER) and Topic Modeling techniques.
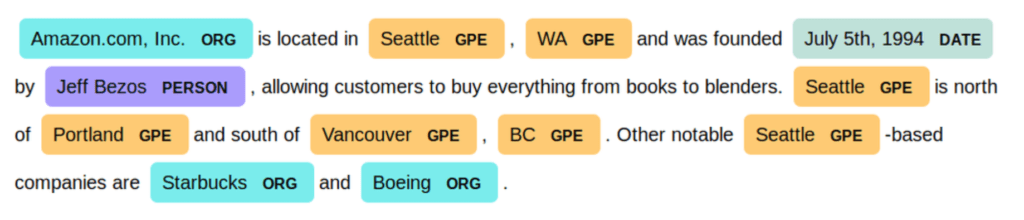
AWS Comprehend is able to recognize entities of standard types using a Detect Entities service (e.g., a branded product, date, event, location, large organizations, person,quality, or title). The list can also be extended to custom entity types. But, you would need to provide annotated documents, which requires additional effort or an entity list, which has its limitations including that the trained model might not be as accurate as if you used annotations. Even going with entity lists, the input data should be prepared carefully as AWS Comprehend’s Custom Entity Recognizer has a limit on negative examples, meaning one should filter down sentences that do not contain a custom entity. The benefit of AWS Comprehend is that custom entity recognition can be made in real time. It is useful for applications that work with short texts, like posts or customer complaints on social media, customer support tickets, etc.
To train a custom entity recognition model using AWS Comprehend, it’s necessary to create an endpoint. After the endpoint is built, AWS Comprehend can be used to detect entities in separate bodies of texts quickly.
There is no built-in NER model in SageMaker.
Using SageMaker and custom NER solutions, we can detect both default and custom entities in real-time based on a deep learning model.
Based on our experience, AWS Comprehend provides a huge list of default entities, many of which are not relevant to a specific case (e.g., quantity, time). The resulting list is overwhelming and needs to be additionally filtered. Whereas, a custom model is tuned during development and it requires no additional effort.
Amazon Comprehend is the suggested topic modeling choice if you have a standard dataset like customer feedback, support incidents, etc. It removes a lot of work associated with topic modeling like tokenization, training a model, and adjusting parameters. Amazon’s SageMaker’s built in LDA or Neural Topic models is perfect for cases where finer control of the training, optimization, and hosting of a topic model is required (e.g., when you deal with specific texts’ domain).
The only available model for Topic Modeling using a AWS Comprehend Topic Modeling service is LDA. Using SageMaker, one can choose out of two available built-in models: LDA or the Neural Topic model, or you can even develop a custom model. Going with any of SageMaker’s options, once the model is trained, we can use it to label new and unseen documents on the fly, with one or more topics found due to a topic modeling algorithm.
In the case of AWS Comprehend, the trained model can not be used to tag new documents. Only texts used as input for the model would be tagged. There is a somewhat limited workaround to label new documents with found topics as well and it will leverage the Custom Document Classification Amazon service. To make a long story short, to tag new texts with topics, we needed to train a multi-label classifier on already processed texts. Here is where the first confusion springs up: topic modeling is a soft clustering task, meaning each document will be tagged with several labels with different probabilities. There is no means to pass this information on to the classifier, which leads to low classification accuracy.
AWS Comprehend’s topic modeling service has a list of limitations, including the number of topics (up to 100) and parameter tuning (choose a number of topics blindly).
So, AWS Comprehend doesn’t seem to be suitable for continuous note tagging and it doesn’t have any advantages in accuracy as it is based on the same (one) model and is not suited for custom data.
Besides, when using Amazon Comprehend services, be aware that your data could be stored and used by AWS later on for training purposes. If you are dealing with PII or sensitive data, make sure to disable the automated use of data by AWS.
The promises of cloud vendors to solve your specific problems with out-of-the-box solutions and with little to no configuration are tempting. Why build it if you can click on or change a few configuration files and make it happen? Let the cloud vendor deal with all those complexities and magic.
In doing so, you have to accept the limitations and the flaws of the black box. Many times those limitations won’t be acceptable to you and unfortunately you will not see them at the beginning of your project.
The other often silent factor is the lifecycle of those cloud services. You build dependency on them, but how long will they last? For how many years will the cloud vendor support them or simply keep them alive?
Really low accuracy from ready-to-use AI services is a common problem well known inside AI circles. Are we advertising not to use cloud services? No, not at all, but be aware of the pros and cons. To use something or not to use something is never our goal; it’s the means and tool, not a goal.
As you can see, the Avenga AI services branch knows how to use out-of-the-box cloud solutions efficiently, and knows when to stop and find another solution in any case where what they provide is not satisfactory. Let us create custom models and solutions to solve your business problems!

Stay informed about the end of support for Microsoft Office 2016 & 2019, Exchange Server 2016 & 2019, and Windows 10.
Ready to innovate your business?
We are! Let’s kick-off our journey to success!






