
Essential updates on software testing trends in 2025 and beyond
Access the state of AI in software testing in 2024, learn the key QA trends, and prepare for the future of software development today.

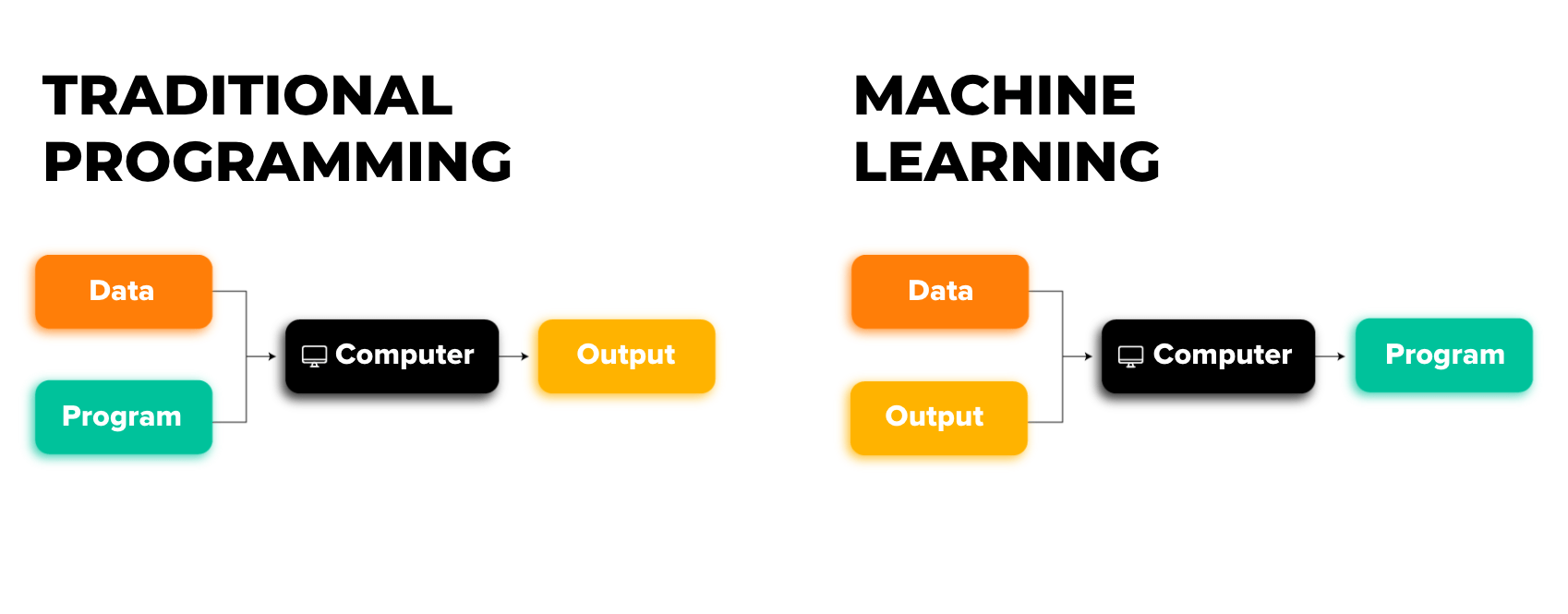
With digital becoming a part of everyday life, software development and programming continually keep revolutionizing businesses, especially across advanced intelligence. We are going to overview the differences between Traditional programming and Machine Learning paradigms.
In Traditional programming, we write down the exact steps required to solve the problem. While with a subset of Artificial Intelligence (AI), Machine Learning is motivated by human learning behavior; we just show examples and let the machine figure out how to solve the problem by itself.
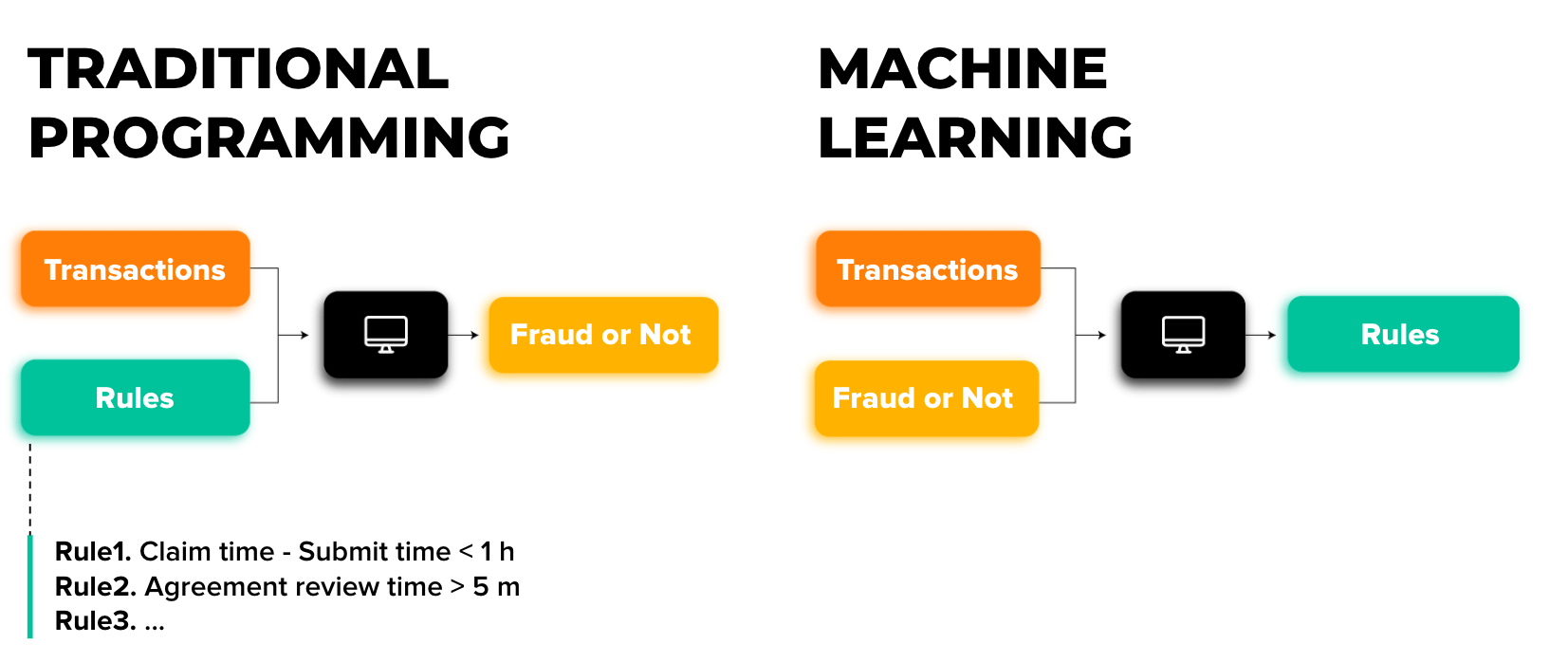
The following is a real-life example of how traditional programming and Machine Learning differ. Imagine a hypothetical insurance company that is striving for the best customer experience in the 21st digital environment, as well as preserving assets and their ROI. So, the automatic detection of fraudulent claims is a part of their business processes.
Consequently, there are 2 possible scenarios of technology stepping in:
Now you may wonder what the actual algorithm behind training the model or ‘learning’ from examples is.
We will explain this concept using an Artificial Neural Network (ANN) example. ANN is the Machine Learning model inspired by the networks of biological neurons found in our brains.
ANNs are powerful scalable tools that tackle complex Machine Learning tasks, such as powering up speech recognition services, classifying billions of images, and automating fraud detection, to name just a few.
→A real case of AI-powered fraud detection
ANNs are heavily used today, although they were first introduced back in 1943. Since then, they have witnessed several rises and winter periods. But now, due to the huge quantity of data available, tremendous increase in computing power, and improved architectures, it looks like ANN is likely to have a solid impact on our lives.
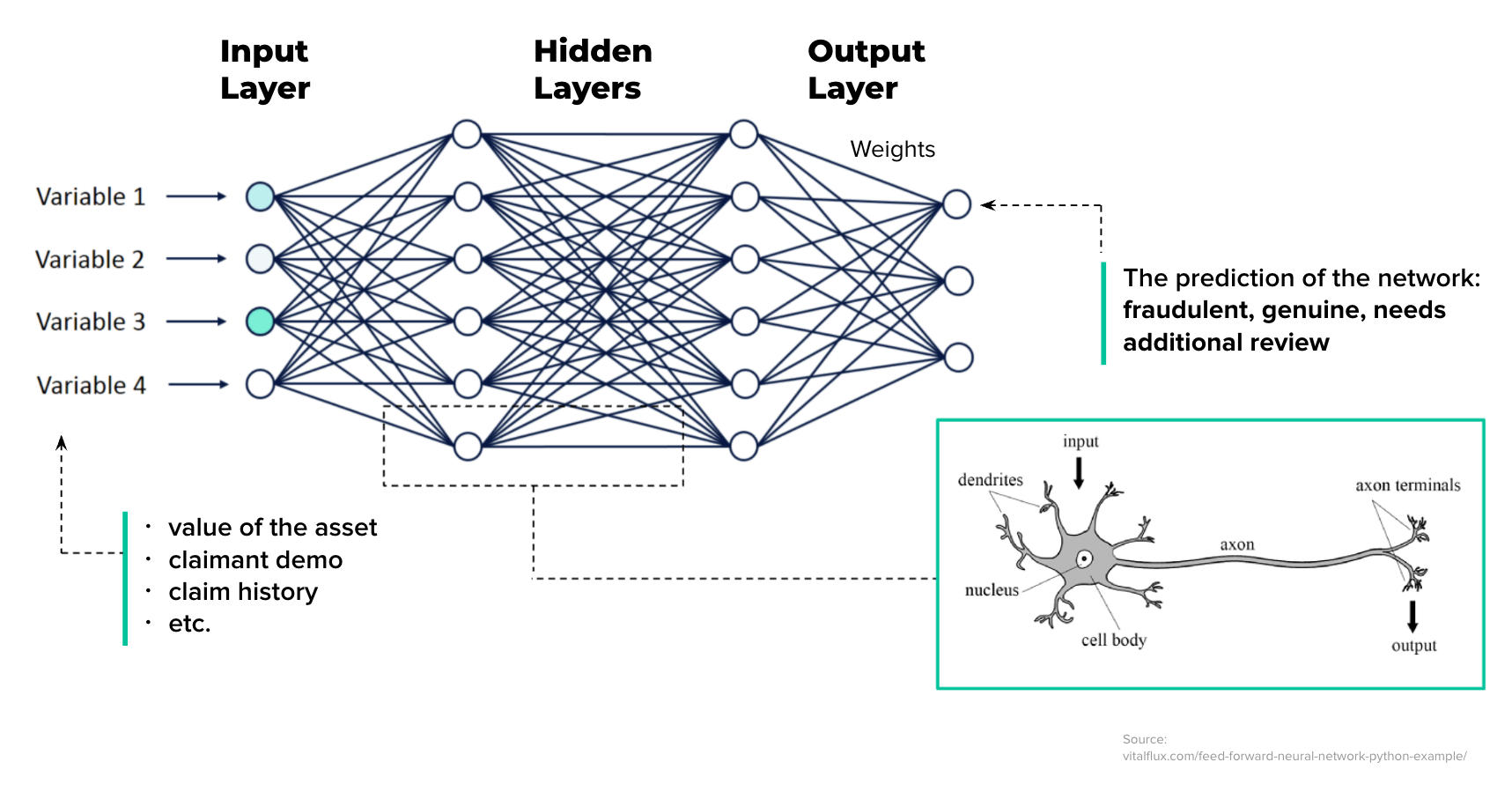
Neural networks consist of layers with each layer consisting of “neurons“. The most interesting thing is that the neurons are just decimal numbers.
The first layer of the neural network is called the input. In fact, this is your data. In the case of fraud detection, these are the features of an insurance claim (value of the asset claimed, the demo characteristics of the claimant, and so on). So in the case of a face recognition problem, the input is the raw pixels in an image.
The last layer of the neural network is the output layer. This is actually a network prediction based on the data you entered. In our example with fraud detection, it’s a verdict: fraudulent or genuine.
All the layers are interconnected and each connection is associated with a weight. These are also just decimal numbers. Knowing the values of the neurons of the input layer and the weights, we can calculate the values of all the other neurons in the network.
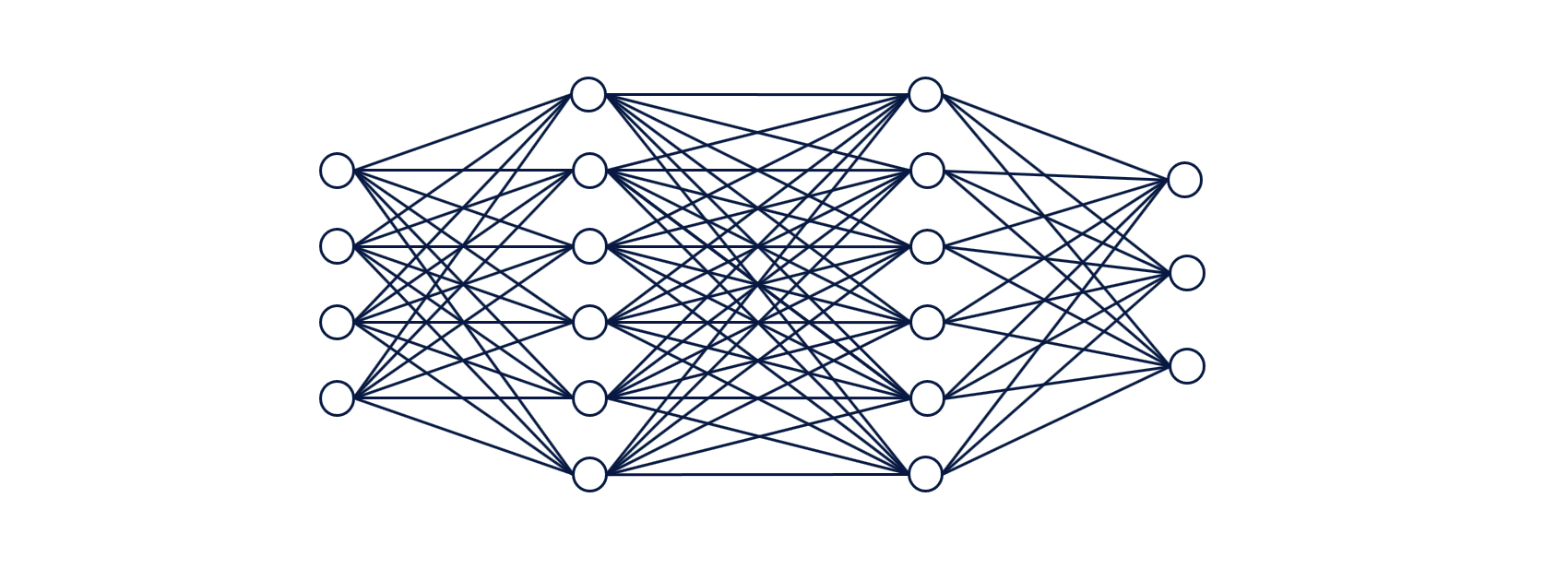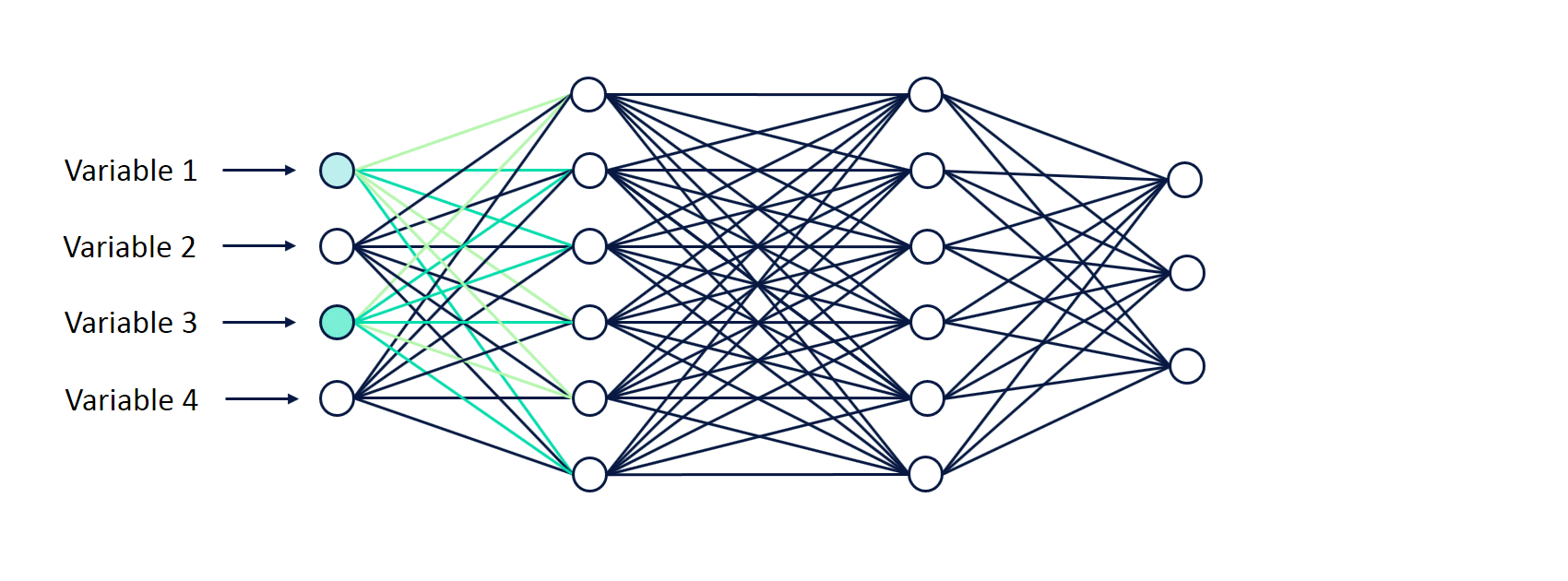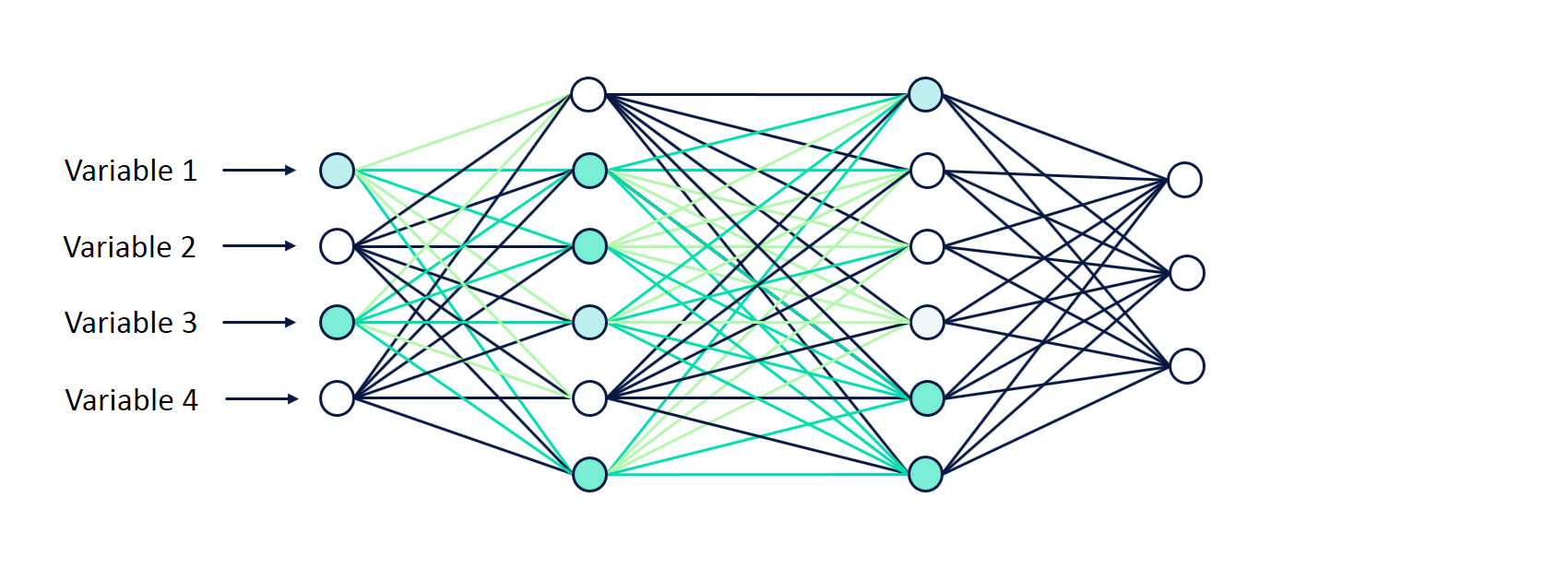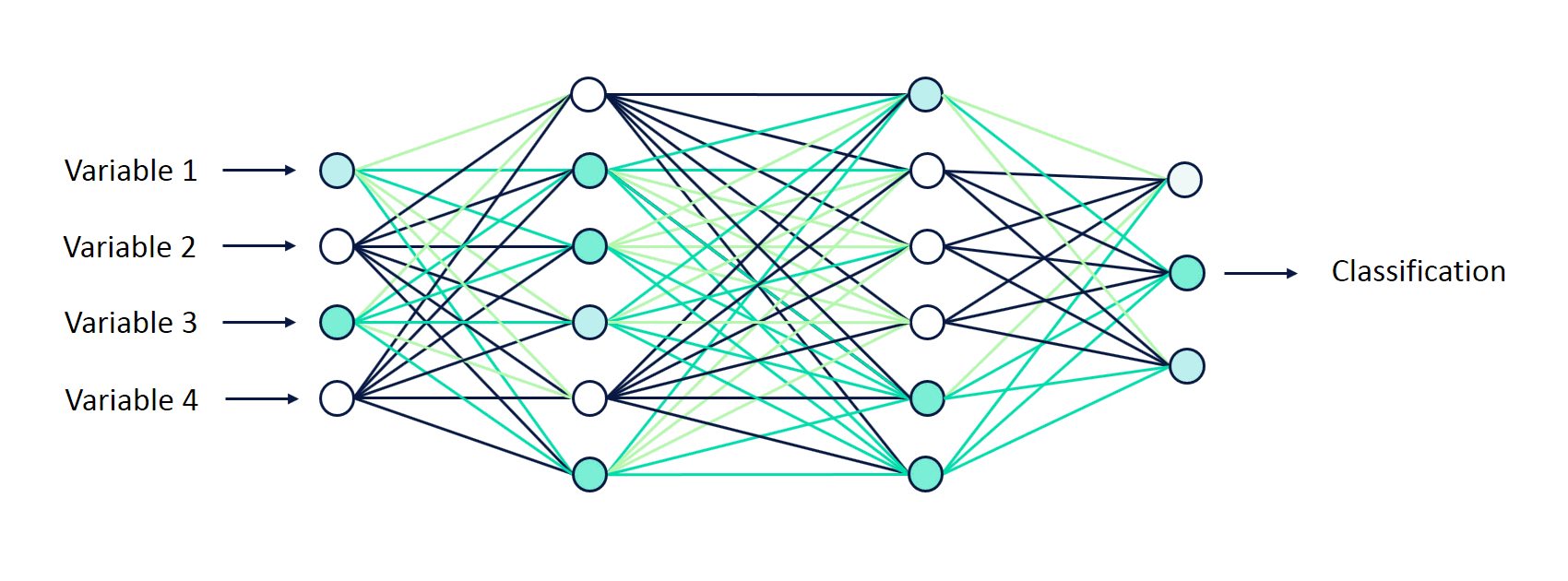
That is, the values of the neurons of the first hidden layer are calculated based on the values of the neurons of the input layer, and the connection weights between the input and the first hidden layers.
This process is called forward propagation.
But, how do we know the value of the weights? Basically we don’t. We need to learn them. And, that’s actually when learning takes place. We can utilize the backpropagation training algorithm for this, which was invented back in 1986, but is still used today.
For each training instance, the backpropagation algorithm first makes a prediction (forward pass) and measures the error.
Then it goes through each layer in reverse order and computes the gradient of loss function with respect to every single model parameter. In other words, it measures the error contribution from each connection (reverse pass). Once we have these gradients, we know how to tweak the parameters in order to reduce the error (this is called the Gradient Descent step).
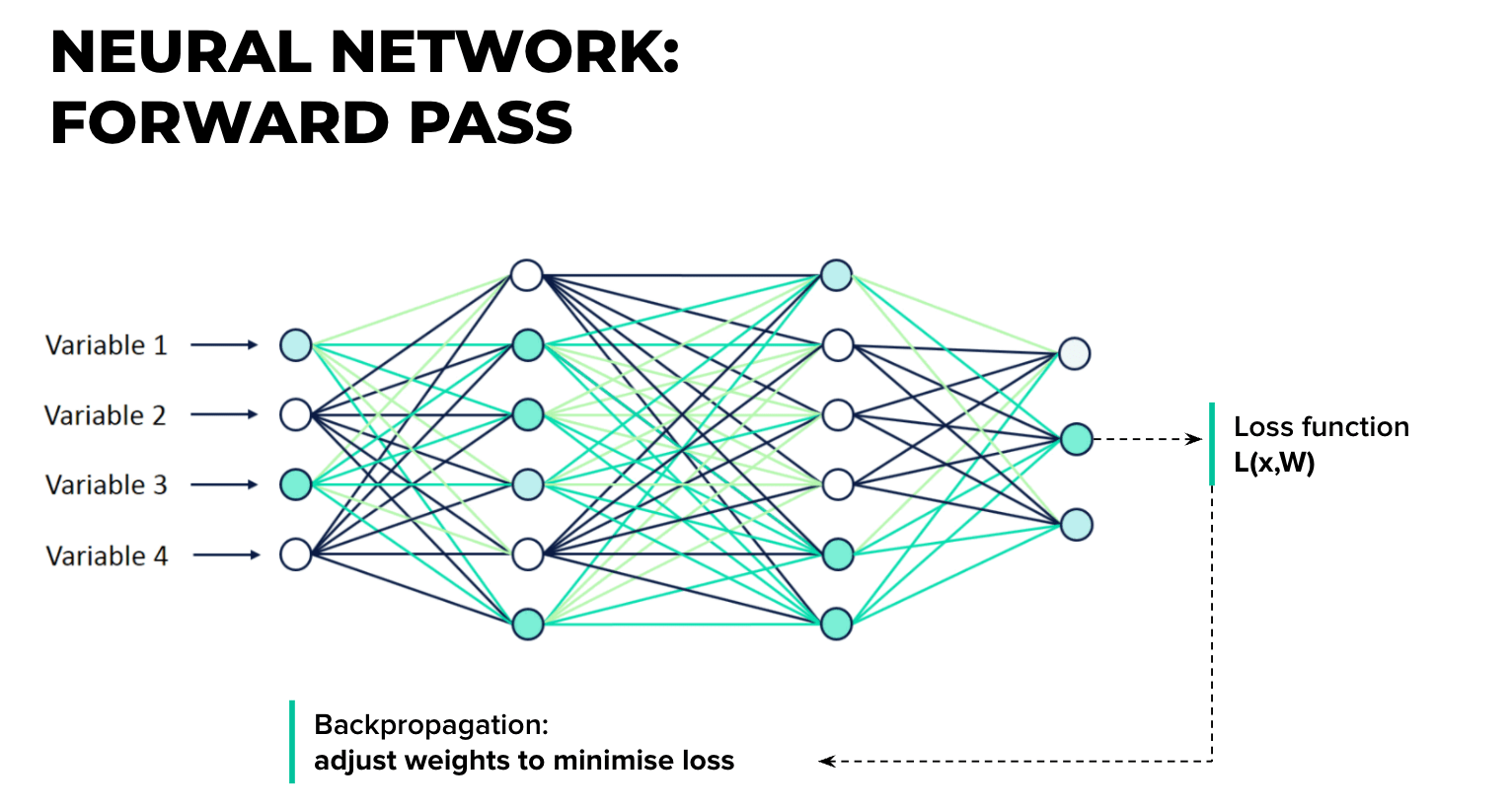
Having walked through all of the above, here are some conclusions:
In a standard ML setup, data is usually collected from one or multiple clients and stored in a central storage. A Data Scientist has access to the data in the storage for doing ML.
A data scientist wants to train an AI model on the data using a predefined ML algorithm. Once the model is trained, they evaluate it on new or unseen data. If the model’s performance is not satisfactory, a data scientist makes some changes to the algorithm, does hyper-parameter tuning, or adds more data. Then they retrain and re-evaluate the model. The Data Scientist keeps doing these steps until the model reaches an accepted level of efficiency.
Once the Data Scientist is happy with the model, they deploy it to the devices where the model will be used to make inference on the device data.
→ Why use Machine Learning to Scale Business Intelligence & Predict Data Outcomes
There are some limitations in standard Machine Learning:
Traditional programming, that is a manually created program with input data producing the output while running on the computer, has been around for quite some time already.
Machine Learning, an automated process of the algorithms formulating the rules from the data, is a powerful way that yields productive insights suitable for later usage to predict business valuable outcomes.

Access the state of AI in software testing in 2024, learn the key QA trends, and prepare for the future of software development today.

Predictive insights, AI-driven automation, and emissions tracking with a cloud! Read what Salesforce has ready for businesses in 2025.

Learn about the state of generative AI in 2025: AI agents, energy-efficient computing, and image processing. These and more AI trends will redefine what we know about technology in the upcoming years.

Avenga, a global technology solutions partner, announces Kannan Janardhanan as Director of Account Management in North America.

Learn how AI is transforming the telecom industry and dive into its power to enhance customer experience in 2025 and beyond.

Watch our free webinar, “AI in Banking: From Data to Revenue,” to explore how AI is transforming the BFSI industry.

Explore a strategy that shows you how to choose a cloud platform for your AI goals. Use Avenga’s Cloud Companion to speed up your decision-making.

Avenga and Qinshift are excited to share the news of Aaron Wall’s appointment as Vice President of Business Development in the US and North America.
Ready to innovate your business?
We are! Let’s kick-off our journey to success!