Intro. What is the Julia language?
In 2009, a group of computer scientists decided to create a new general purpose language. Julia 1.0 was released in August 2018, and recently we celebrated the important 1.5 release.
What is the Julia language then? What are the promises of the creators, language specific facts, adoption challenges and opportunities? What is its future?
How does it compare to Python, Matlab and R?
The promise. Goals of the Julia language
They created a manifesto in which they stated that they wanted to combine requirements, which seemed impossible to achieve at the time. The new language had to be both interactive and near-C fast, while type safe and dynamic at the same time. Another requirement for any new language always is: it has to be easy for developers to learn, otherwise it’s doomed from the start.
This time the promises are really bold – let’s verify the claims.
Performance
Julia is one of the few languages that are in the so-called PetaFlop family; the other languages are C, C++ and Fortrant. It achieved 1.54 petaflops with 1.3 million threads on the Cray XC40 supercomputer.
Julia’s notable uses are climate change analysis, NASA simulations, risk calculations in large financial institutions, and astronomical datasets, so there’s no doubt Julia has proved itself in large scale, high performance and scalability demands.
→ Explore Essentially, Data is good. It’s the use cases that can be problematic
Scalability
Julia is believed to have unlimited scalability. There are examples of Julia applications running with . . . millions of parallel threads.
Interesting facts. What makes Julia so special from the developers’ perspective
Instead of writing another “Hello world” tutorial about Julia, let us share with you our observations and what makes Julia so special from the developers’ perspective.
A language is always compiled using a just-in-time compiler. It means the code runs very fast, but there’s a ‘ahead of time compilation’ which results in an execution. For instance when running Plot libraries for the first time, it is felt directly (tens of seconds for compilation required for each Jupyter notebook).
Despite being a fully compiled language, Julia’s distribution contains a command line interactive mode which enables immediate results and experimentation.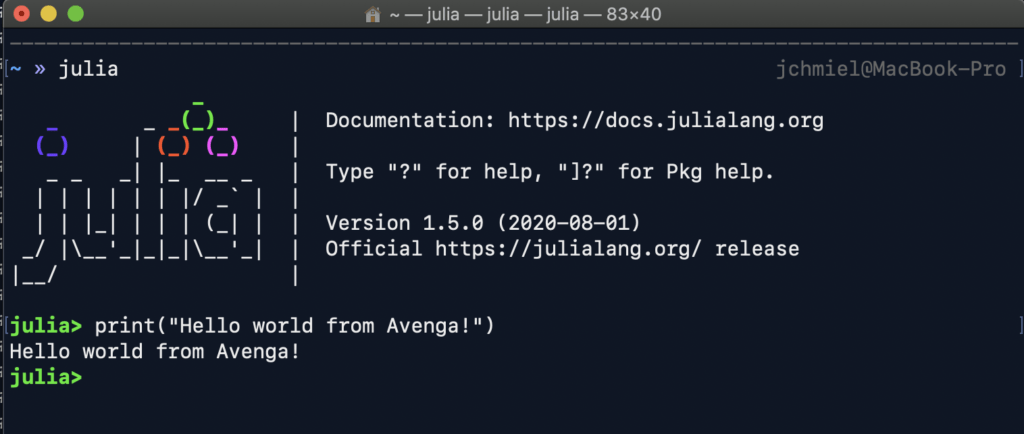
- For instance, Julia is a primarily functional language with strong mathematical enhancements, so you can declare functions almost 1:1 as mathematical functions:
- Julia has many mathematical operators built in (like power). Also set operators like to get all the elements belonging to the set.

- There’s strong encouragement for writing tiny, even single line, functions. The cost of functions is very low. If they are called, they usually won’t be invoked as functions but inlined by the compiler with a zero call overhead.
- There are global and local variables.
- NULL? There’s a nothing keyword.
- Semicolons ; are not required, however, they can be used. Their role is to suppress the output.
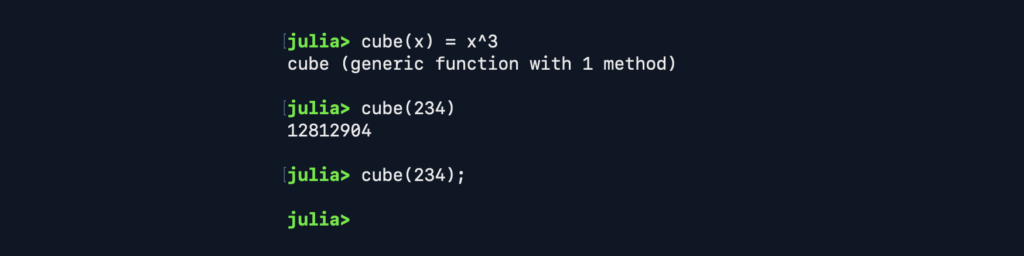
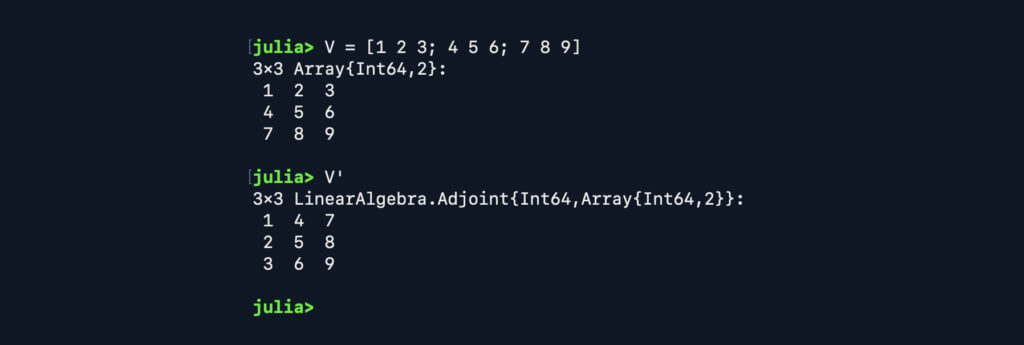
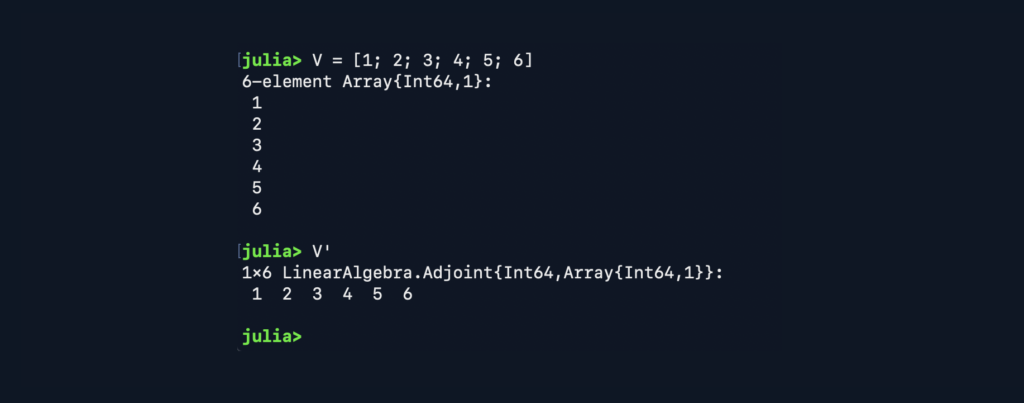
- The operator ‘ turns a vector from vertical to horizontal (transposition).
- Simplified vector operators are for massive generation and modification of data. For instance, here we generated a vector of true / false depending on the random value and criteria.
Note that in most other languages it would require a loop with adding elements to the vector/dynamic array. Here it’s a single line.
- Tuples are natural language constructs, similar to fixed size arrays, with a strictly defined type and size.
- Macros are another layer of flexibility. They are code generators that enable even more dynamism of the language.
- Generic programming – functions can be passed as parameters, enabling generic algorithm implementation to remain unmodified (for instance, strategy pattern implementation).
- Strong typing – yes, if you want it, no if you don’t. Explicit typing helps with the code performance and enables the compiler to detect errors earlier.
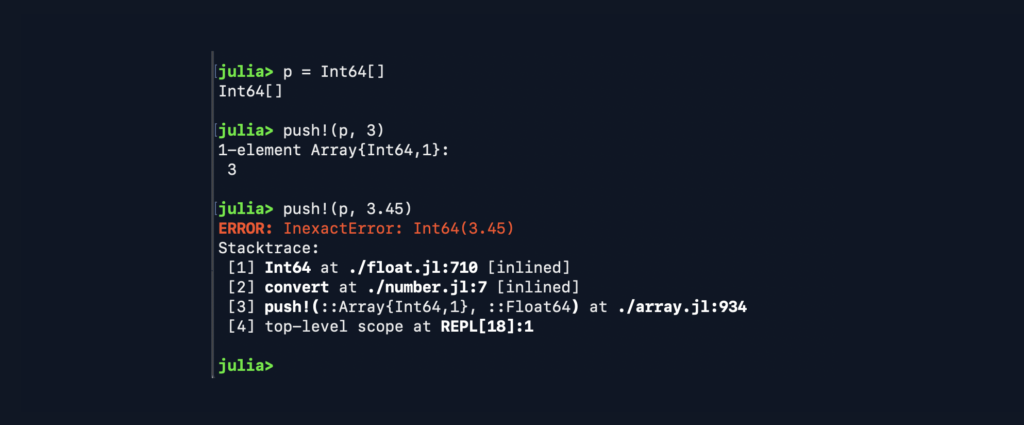
The dynamic version is the following:
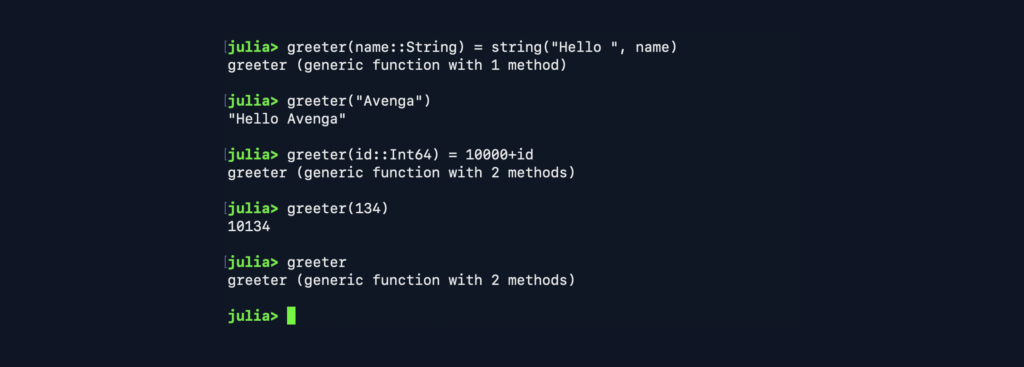
- Multiple dispatches enable functions to accept a various number of parameters with different types. This language feature is used very frequently; for example, a rand function has more than 60 variants.
- Memory management is automatic (garbage collection).
- Julia’s parallelization is lightweight, compared to Python, and there are synchronization routines as well as asynchronous channels.
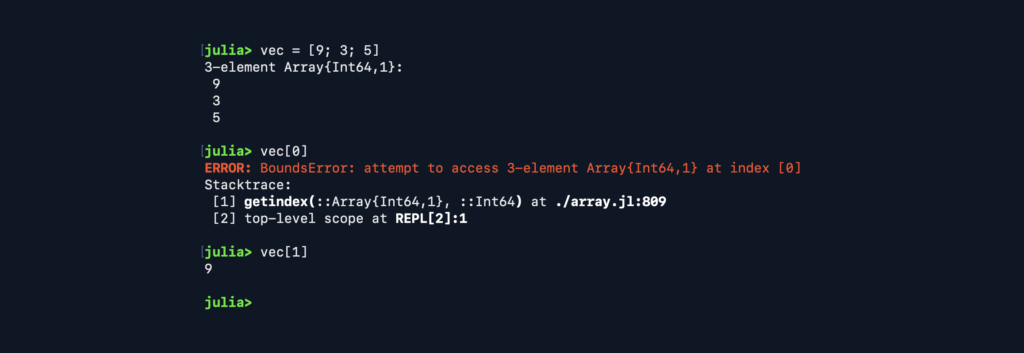
- Julia indexes are from . . . ONE (1), not from ZERO (0).
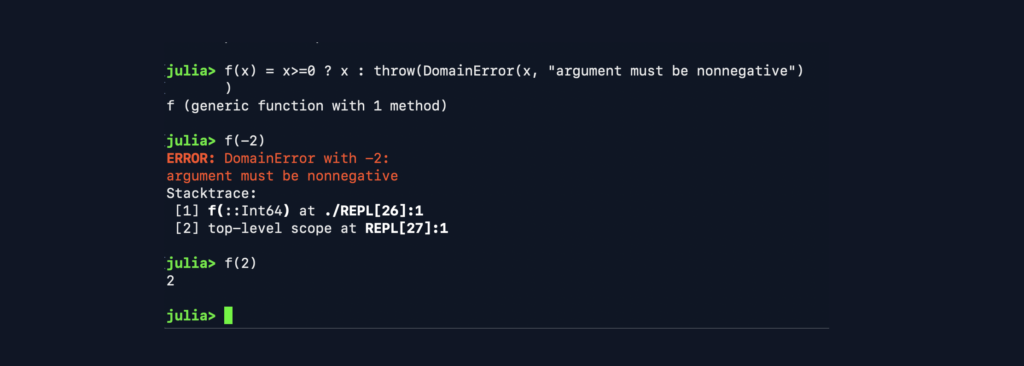
- Exceptions can be thrown and catched.
- Inheritance? There’s a composition over the inheritance paradigm in Julia. There are structs that contain the data and functions that operate on the structs.
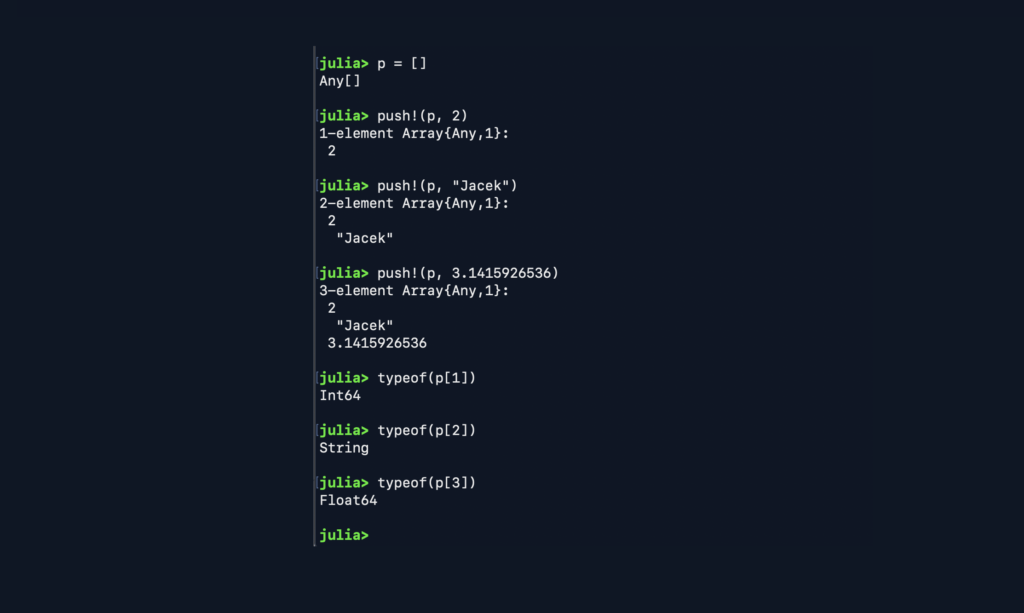
Data visualisation
The key for data visualisation is in the Plots module.
It supports many types of graphical representations of data, from simple lines and points, and histograms to complex 3D images.
Also, to visualise the data’s dynamic aspects, animations are possible.
There’s a macro @gifs that creates GIF images from the data.
There are multiple supported back-ends (renderers), which provide options to choose from, including Javascript based interactive ones.
→ More about BI and Data Visualization expertise by Avenga
Themes can be added to change the style of the data visualisations in a consistent way.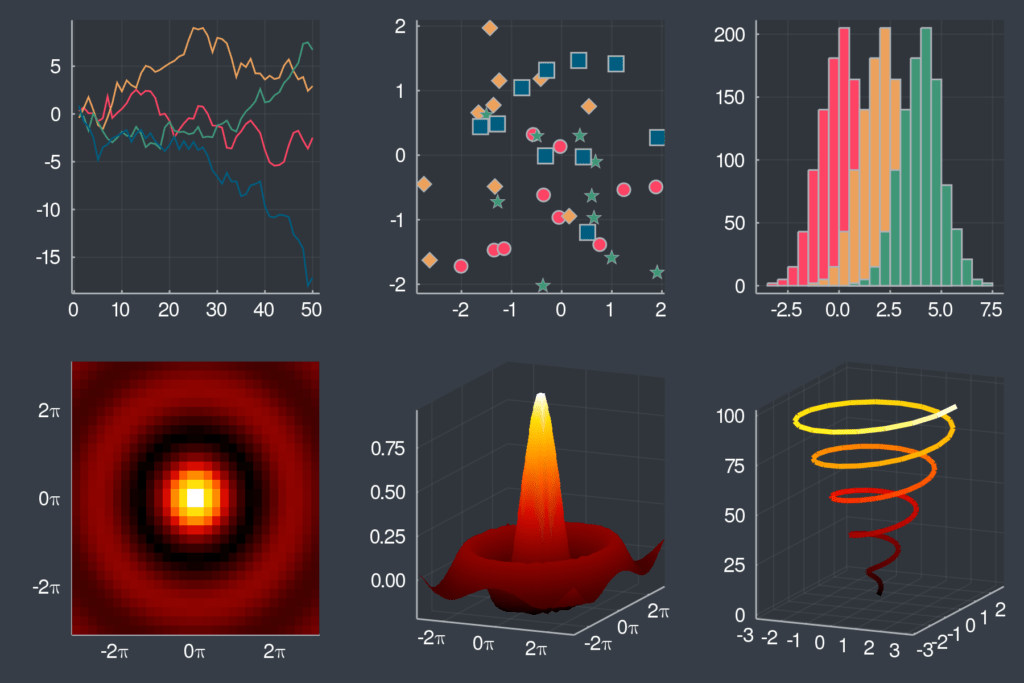
Let us see a few examples from the notebook.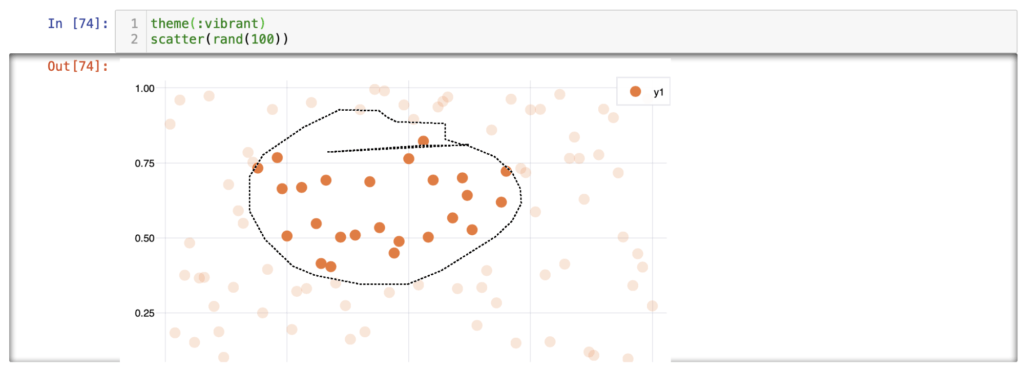
A lasso selection of a group of interesting data (interactively).
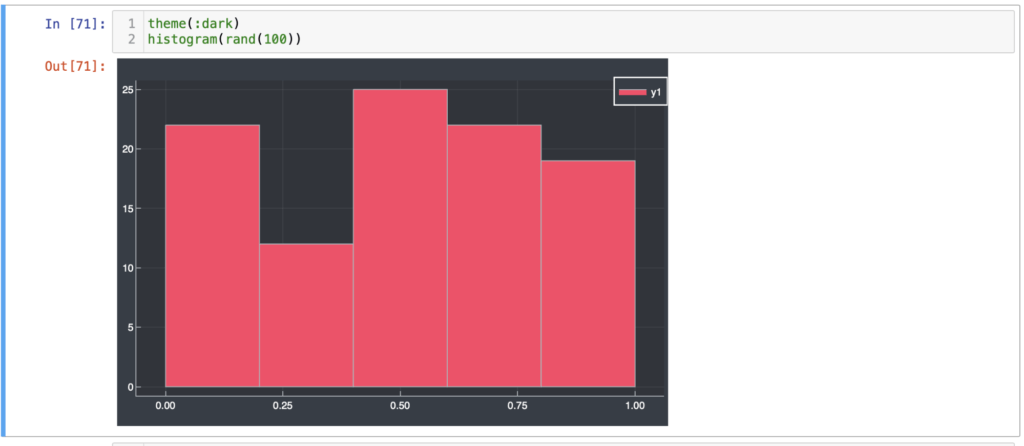
Histogram with dark mode.
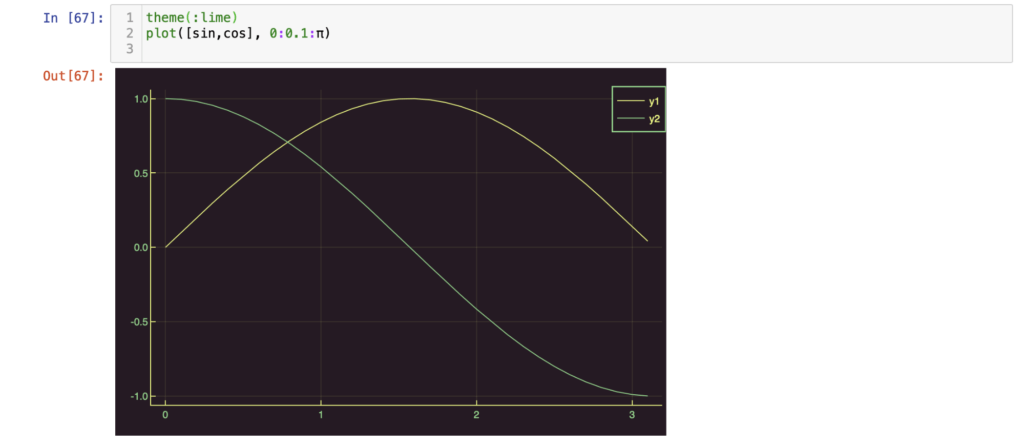
Sin and cos lines using the lime theme.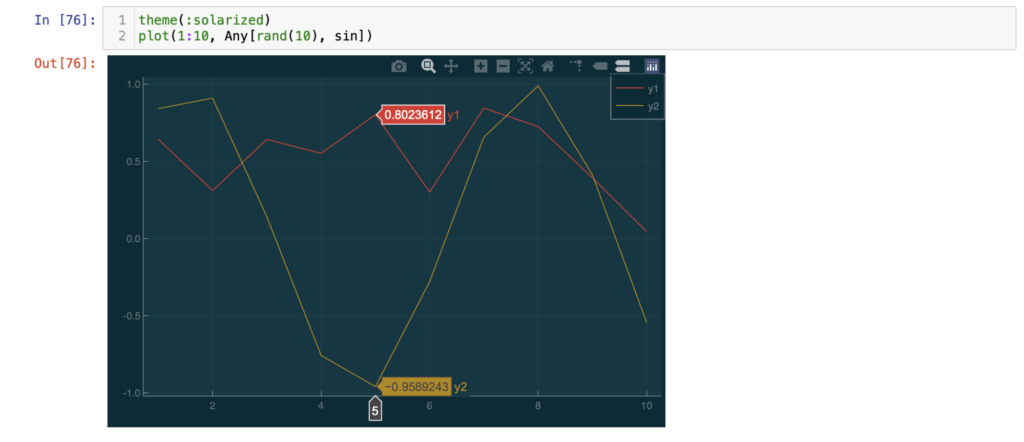
Two random lines using a solarized theme; note the interactive point selection.
Adoption of Julia programming language. New vs tried and tested
Simply too new
One of the common misconceptions is that Julia is a very new language and it simply needs more time to become popular.
It was launched in 2012, so yes, it’s new compared to Python or R, but it’s not last year’s revelation. The counter argument is that the 1.0 version is from 2018, and before 1.0 serious enterprises wouldn’t even look at it.
Python dominates the data science world
An assumption is that Julia addresses the limitations and performance problems of Python, from its beginning and is designed from the ground up to be fast and scalable. It is also more type safe than Python. And, it’s all true.
But neither Python nor R have been static in the last 8 years. There are new improvements which make the advantages less obvious.
Bare Python definitely lacks the features of Julia for algebra and data processing, but with libraries like NumPy, Python easily becomes the dominant force. And, those libraries had years to become stable, feature rich, and widely known by millions of developers.
Another problem for Julia is the community size. For Python, it has millions of active developers so it’s the primary choice, and it has total domination in the data science and machine learning space.
→ Read more about Data science perspective on Covid-19: a real life example
When a new team is built for these kinds of projects, the availability of resources is one of the key factors, and starting with Julia doesn’t help.
Julia is currently measured by the number of downloads of its runtime, more than in the number of active developers (TIOBE #31, 0,47% at the time of writing this article).
→Read more about Full cycle development and developers
What about R?
The Julia language is not a general programming language, however the R language is specific for data manipulation and statistics.
Despite previous doubts (the R usage was getting lower and lower), now we are seeing the resurgence of R’s popularity as it moves fast up the TIOBE index.
According to many scientists, Julia is still not on par with R’s statistical and data visualization capabilities, and in order to be a successor to R, there’s a lot of work needed.
This is really interesting: in the first half of 2020, the need for statistical analysis of data surged, and that meant the spike in popularity of R, not Julia.
Another very important problem for Julia is the tens of thousands of libraries available, even more than for Python.
Julia vs MATLAB
Matlab is, or was, another popular environment for the statistical analysis of data. When replaced with Julia, users experienced 10 times or more speed improvements; they considered the language to be fast.
Live and let live
Julia creators are fully aware of the situation, so they built Julia to be able to cooperate with code written in Python and other languages. So, Julia can be an interesting augmentation of existing code, but not a total replacement. Because of its speed, close to the C language. The previously inevitable C-libraries are helping to overcome the speed limitations of Python, and now code can be written in the more developer-friendly Julia.
Not only data science
Julia can also be used for systems programming due to its fast performance and scalability; similar to Rust or Go. There are various types of servers written in Julia.
→Read more Rust language – the most loved language of them all
Julia code can also be compiled to Wasm and be used in the browser on the client’s side.
Proof of concept – Mandelbrot fractal in Julia. First-person experiment
The goal
The goal of the task was to generate Mandelbrot fractals using Julia in a Jupyter Notebook.
Why? Fractal image generation requires lots of CPU power, so it’s someplace that Julia should be able to prove itself as a good tool.
Results
Images speak more than a thousand words. 
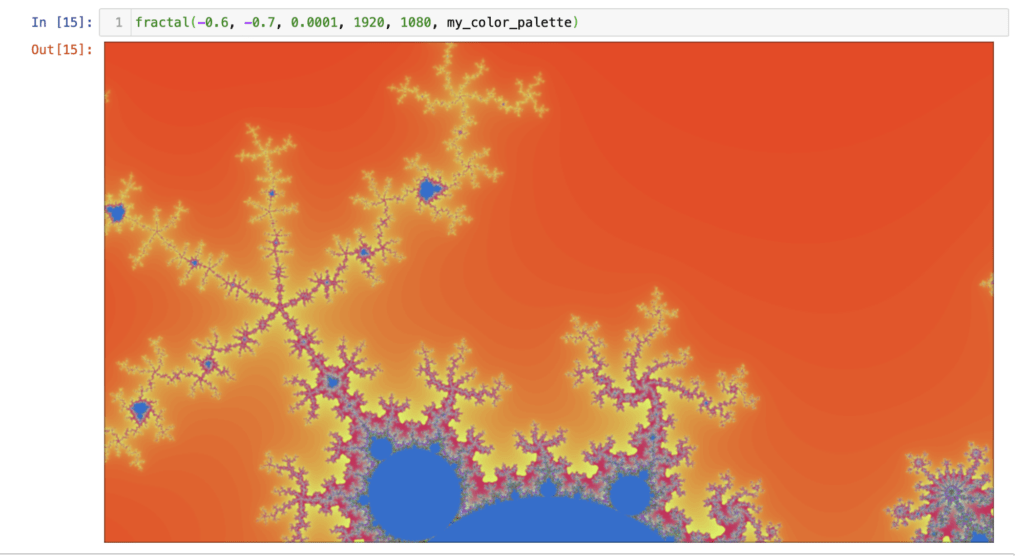
So as you can see, it definitely works.
And don’t worry, you’ll be able to play with it yourself because everything is shared in our GitHub repository (https://github.com/avenga/julia-fractals).
Solution step by step
Preparation of the environment:
I installed Julia runtime on my OS:
brew cask install julia
Then I launched Julia and started the Jupyter Notebook in the browser. Using Pkg
Pkg.add(“IJulia)
using IJulia
notebook()
Beware: your configuration may be different, so more dependencies may have to be added.
Download notebook from GitHub
Just clone our Avenga Julia fractals repository – the single AvengaLovesJulia-fractal is there.
git clone https://github.com/avenga/julia-fractals
Now we can browse and open the Jupyter notebook, so let’s take a look.
Environment test
using Pkg
Pkg.add("Images")
So I used the package manager to install the Images package to be used later.
Testing the environment
In Julia, the images are arrays, so once you create the array with the proper type, you can then use the Images package, and it will be displayed as an actual image.
So, now we know the Images package and the Jupyter notebook like each other and work perfectly together.
Preparing a color palette
What if we want our fractal images to be colorful?
I started with a random color palette, then decided to generate gradients automatically.
What is nice is that you can see the palette immediately and play with the generation formula.
For instance, it’s getting less “red” because of the (256-i) modification.
The size of the palette seems to be hard coded here; it can be from a few to thousands of colors, so it depends on your preferences. The fractal image generation function takes its length automatically.
Fractal image function
I used the optimized fractal image generation algorithm from: https://en.wikipedia.org/wiki/Plotting_algorithms_for_the_Mandelbrot_set#Continuous_(smooth)_coloring
I adapted it to Julia and changed the color selection to be a modulo of color palette size.
The function accepts start coordinates (top left corner) in absolute values, scaling factor (0.0004 and similar), then width and height in pixels, and then the array/vector with the RGB color palette of your choice.
What is returned is the image itself. 
Action!
Let’s see it in action.
The entire Mandelbrot set first.Then a fragment of it (zoom, zoom, zoom).

And even more zoom . . .
And a wider view: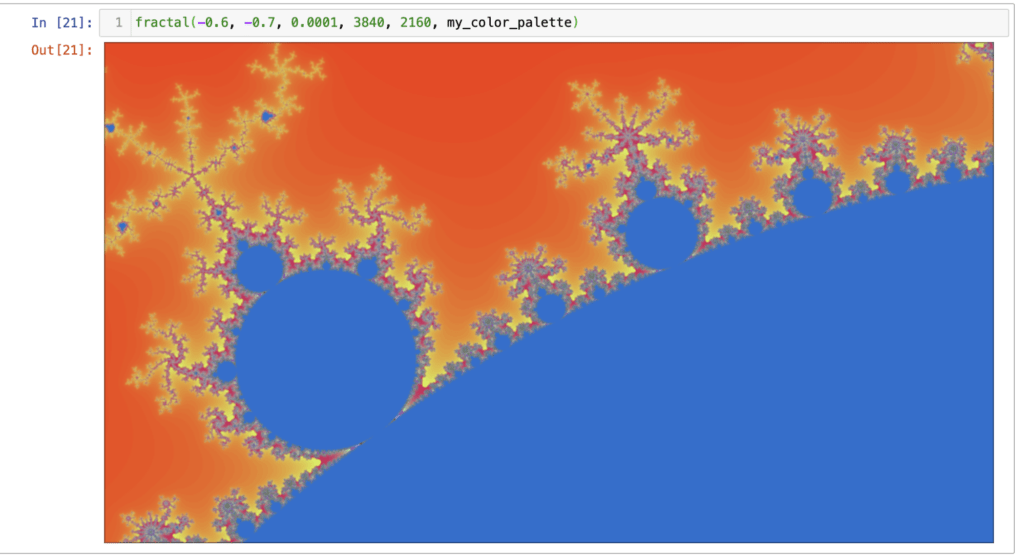
And with a different color palette (night mode 😉
Suggested future improvement
Multithreading – done!
This algorithm begs to be parallel. All the pixels are independent of each other so it’s possible to group processing for the maximum number of threads of a given machine.
Actual pixel generation can be extracted as a function and started in separate threads.
And it was extremely easy with the Julia built-in macro Threads.@threads for multi-threaded for loop.
The speed increase was immediately visible (12 threads on my laptop).
Piece of advice: remember to add the env variable, because by default Julia runs in a single thread mode to your .zshrc file.
export JULIA_NUM_THREADS=12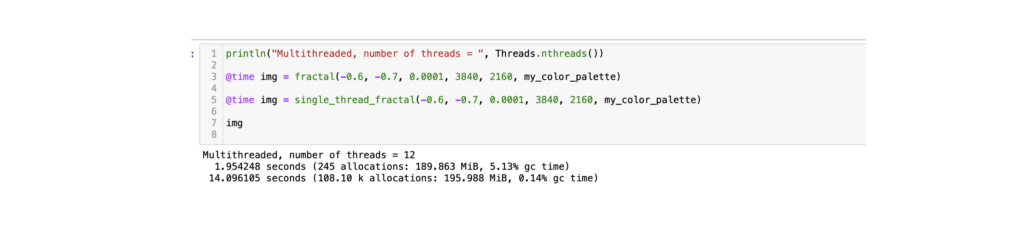
In my case, it was a 7x better performance than the single-threaded version.
Impressions from fractal POC
Let’s start with the cons. Actually a single con.
The only thing that was annoying was that indexes start from ONE not zero.
Look at this line:
color_index = 1 + floor(Int, iteration) % color_palette_size
Adding one to the index? The last time I did that was in the 1980s, when I was a Pascal programmer.
I like the Julia language a lot. The error messages were very informative and once compiled, the speed of execution was really visible and impressive.
I hope we enter the era of not wasting computing resources, like with Python, PHP, or even Java, but use the new family of fast compiled languages such as Julia, Go, and Rust . . . that will take over (a dream, not a prediction).
What is the likely future of the Julia programming language?
Now we face the situation in which Julia is liked by newcomers and considered a breath of the fresh air compared to the aging Python. It is production ready and is mature enough to be used in small, medium, and even the most sophisticated data projects. The scalability and performance is impressive indeed. For me, trying this language was a pure pleasure. I was surprised at how rich it is and how many tricks it has for even faster coding.
So, the Julia language seems to be definitely liked by the community, especially those fed up with the dynamic nature and low performance of Python, and the resulting problems (debugging, errors).
In my opinion, it depends the most on . . . Python developers. Will they be more open to Julia, learn it, try it, or switch to it massively? Until then, Julia will continue to be an important niche player in the data science area.








