

Driving meaningful connections and enhancing customer engagement in life sciences
Learn about the most critical aspects of customer engagement and how to build and implement a reliable strategy for long-term success.

Long story short, Avenga’s R&D department has got a surprising task to emulate a hardware version of Conway’s Game of Life using Java threads (don’t ask me why). We actually needed an emulation of Conway’s Game of Life with slightly modified rules, requiring threads independence. Traditional Java threads are a perfect choice for the task but we were not looking for easy solutions. So, we decided to try CUDA and then Loom. As you may assume our research ended up with the journey a little bit long and far from the initial target. But keep patient, as we hope you will like it.
To begin with, a few words about Conway’s Game of Life (or simply Life) and modifications we need. I promise this intro will be interesting even for old-school coders who know what Life is.
Conway’s Game of Life is founded on the basis of an older and wider concept called cellular automaton which was originally described in the 1940s by well known John von Neumann and less known (but not for our Lviv-based R&D team) Stanislaw Ulam, a Manhattan Project contributor, who was born in Lviv.
A cellular automaton is a collection of “colored” cells on a grid of a specified shape that evolves through a number of discrete time steps according to a set of rules based on the states of neighboring cells.
The definition above comes from Wolfram MathWorld, which is an eponym of another interesting scholar fascinated by automata – Stephen Wolfram.
Conway’s Game of Life itself was described by John Horton Conw ay in 1970 (who, by the way, died very recently after COVID complications) Conway used a 2D square grid where each cell had 8 neighbors.
Every cell in the grid (world) is either black (dead) or alive (white). Each evolution step (world generation) unfolds four various action scenarios:
These simple rules produce interesting patterns that sometimes cycle in the time and can resample moving “organisms”, “flowers”, “bacteria” etc. Below is depicted a well known cyclic pattern called pulsar.
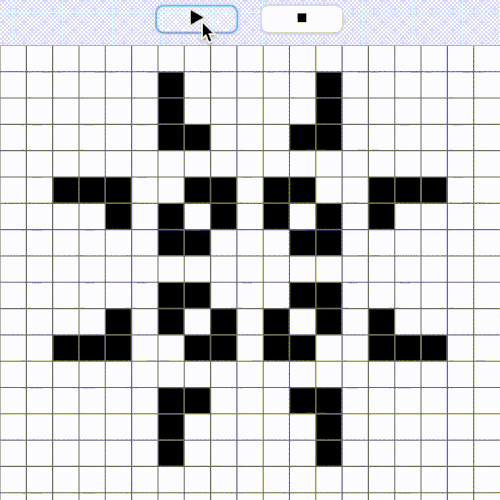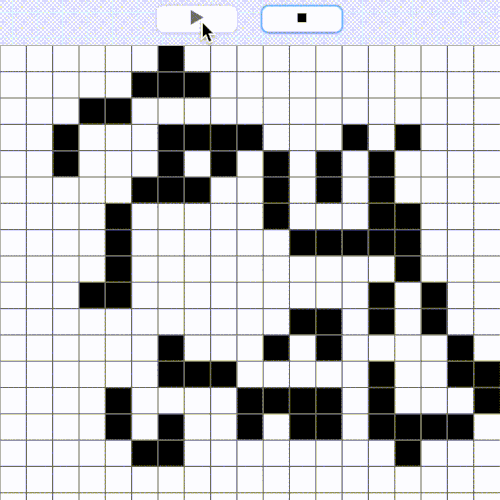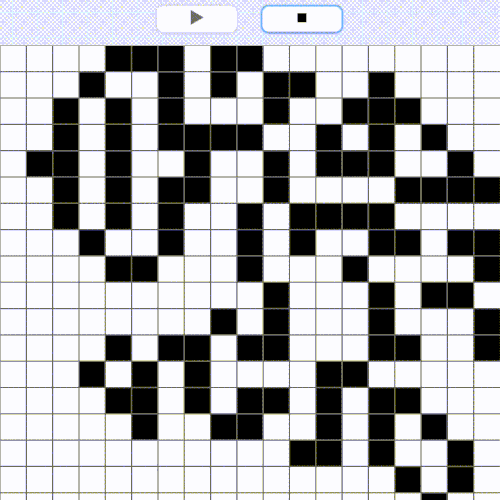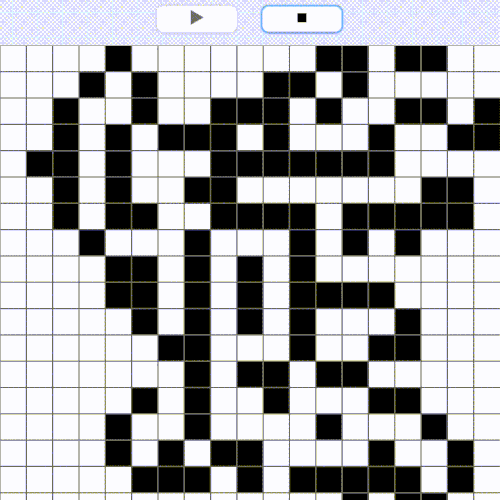
Figure 1. Pulsar (period 3) pattern from Conway’s Game of Life
Some modern modifications of The Game of Life can be truly impressive. Below you can take a look at an example which is using a neural network as a complex rule deciding whether a cell will dye (white) or not (colorful). This network was specially trained to regenerate “tissues” of stable multicolor pattern. The rule is applied to more than 8 neighbors.
Figure 2. An advanced example of cellular automata
The Lizard example seems impossible for standard automaton rules, which would have the cell generation dependent on the previous generation. But if we loosen the restriction for the cell of a new generation to wait until all ancestors have been calculated and make it aware of a much bigger number of its neighbors, a miracle of Life becomes possible. The scenario with the loosen generation restriction is very interesting for us as well.
The first instrument we decided to use was traditional Java threads. We started from the simplest case (Scenario 1), which was iterating to our target case with independent cells (Scenario 3). Then we were changing the instruments while trying to reproduce the same scenarios.
Scenario 1. In this scenario we have threads fully synchronized by the main thread. To calculate the next generation we simply run as many threads as our whole field has cells with the only task: check the neighboring current generation cells, fill out the result to the new generation matrix and die.
The thread’s start is expectedly a heavy operation so next generation calculation for 10,000,000 px. takes a couple of minutes. However, our individual thread accomplishes a very short task so we observe linear (Figure 3) dependency between cells and generation time without memory (Figure 4) or CPU problems (Figure 5).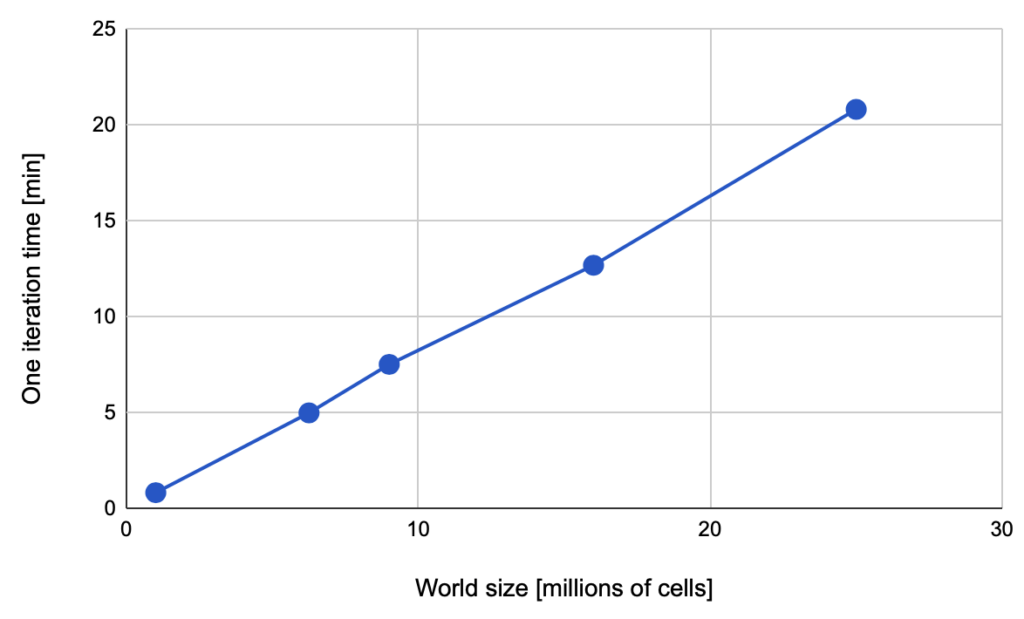 Figure 3. Game iteration duration
Figure 3. Game iteration duration
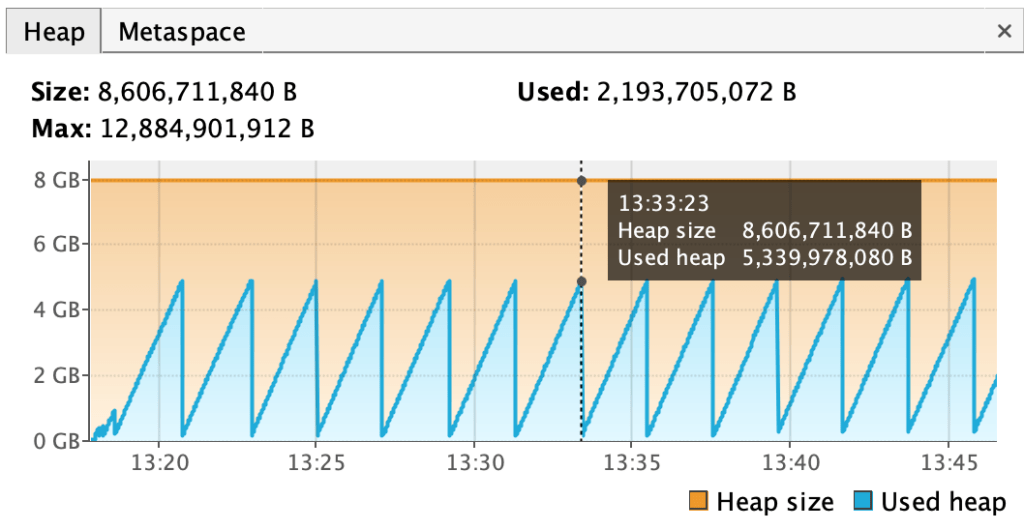 Figure 4. Heap usage of basic application for 25M world
Figure 4. Heap usage of basic application for 25M world
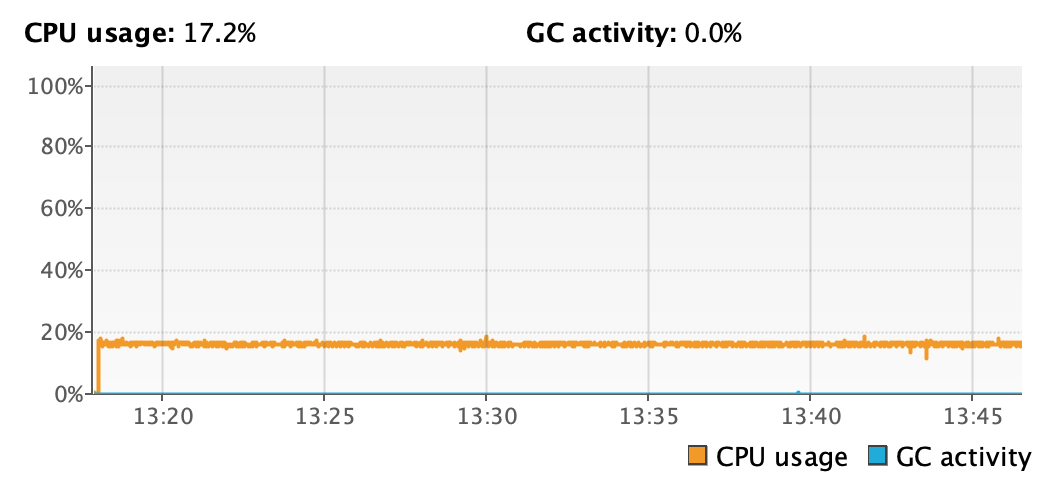 Figure 5. CPU usage of basic application for 25M world
Figure 5. CPU usage of basic application for 25M world
Code sources are available on our GitHub.
Entry point: LifeApplication.java.
You will find the environment used for Scenario 1 in the table below.
| CPU | 6-Core Intel Core i7@2,6 GHz |
| RAM | 16GB DDR4 |
| OS | macOS Monterey |
| JRE | OpenJDK Runtime Environment Temurin-17+35 |
Table1. Traditional environment
Scenario 2. In this scenario, we have independent threads, but still synchronized. As for Scenario 1, we are running one thread for each cell on the field but now threads live “forever” and can calculate generation by generation. To synchronize generation calculation, we use a barrier implemented by passing the generation version from one thread to another.
Of course we hit concurrent threads limit and where able to run only 63*63 field (<4000px). We still can raise the number of concurrent threads by lowering the default stack size but it won’t help to run millions of threads. This scenario failed in terms of huge fields but we’ve got a hope to emulate asynchronous Game of Life in a 64*64 field.
Code can be found on the same GitHub repository.
Entry point: DecentralizedGameApplication.java.
Property: cell.sync=true
The environment is specified in Table 1.
Scenario 3. We are removing the threads barrier for the generations control letting them float free to simulate the modular hardware version we initially needed. This approach is closer to real-world biological cells where cells from the leg know nothing about cells from the arm.
We are limited by a 64*64 field but it’s working! Pulsar is broken and is not periodic anymore; yet, Life is supporting itself (see Figure 6).Figure 6. Broken pulsar pattern
Code can be found on the same GitHub repository.
Entry point: DecentralizedGameApplication.java.
Property: cell.sync=false
We’ve got what we wanted in terms of checking Convey’s Game of Life behavior for non synchronized generations, but 64×64? Seriously? What about GPUs with their multiple hardware cores? Let’s check.
Coming at a similar price and within the same power envelope, a Graphics Processing Unit (GPU) provides considerably higher instruction throughput and memory bandwidth than a CPU.
This difference in capabilities between the GPU and the CPU exists because they are designed with different goals in mind. While the CPU is designed to handle a wide-range of tasks sequentially taking into consideration user clicks, hard drive access, etc., GPU is designed to simply run huge amounts of small concurrent operations handling massive 3D rendering tasks.
Therefore, GPU dedicates more transistors to data processing instead of allocating them to data caching and flow control. Applications with a high degree of parallelism can exploit this massively parallel nature of the GPU to achieve performance higher than the one of a CPU.
A GPU is built around an array of Streaming Multiprocessors (SMs). A multithreaded program is partitioned into blocks of threads that function independently, so that a GPU with more multiprocessors will automatically execute the program more quickly than a GPU with fewer multiprocessors.
To access those multiprocessor capabilities for tasks like our’s, GPUs provide general-purpose platforms; in NVIDIA’s case the one’s called CUDA.
CUDA (or Compute Unified Device Architecture) is a general-purpose parallel computing platform and programming model that leverages the parallel compute engine in NVIDIA GPUs to solve specific computational problems more efficiently than on a CPU. CUDA comes with a software environment that allows developers to use C++ as a high-level programming language.
We’ll dig a little bit deeper into the CUDA programming model to understand how the main concepts of this model are presented in general-purpose programming languages like C/C++.
The CUDA programming model provides an abstraction of GPU architecture that acts as a bridge between an application and its possible implementation on GPU hardware. Main concepts in this abstraction are the host and the device.
The host is the CPU available in the system. The system memory associated with the CPU is called host memory. The GPU is called a device, and GPU memory is likewise called device memory.
There are three main steps that enable executing any CUDA program:
CUDA C++ extends C++ by allowing the programmer to define C++ functions, called kernels, which, when called, are executed N times in parallel by N different CUDA threads, as opposed to being executed only once like in regular C++ functions (Figure 7).
A kernel is defined by using the __global__ declaration specifier. Each thread that executes the kernel is given a unique thread ID that is accessible within the kernel through built-in variables.

Figure 7. The kernel is a function executed on the GPU
Since we are running our research on Java, we need a way to run CUDA from Java, and it’s not hard to guess the name of such a tool. Yep, the right answer is JCuda.
JCuda allows you to interact with the CUDA runtime and driver API from Java programs. The main usage of the JCuda driver bindings makes it possible to load PTX- and CUBIN modules and execute the kernels from a Java application.
You need to install the following tools to use CUDA on your system:
Unfortunately we were unable to make the GPU vs CPU battle very clean and run it on the same machine but perfect performance comparison was not our goal and even our setup gives the clue regarding weak and strong points of different approaches
Scenario 1.
Now, our game is a representation of a 1D grid of cells. The application handles the processing of every cell in a separate kernel thread.
We have CudaGridProcessor, which allocates memory for the 1D grid on the device, launches the kernel function (see Listing 1), and reads results from device to host (one game generation).
Kernel function (CudaCellGenerationKernel.cu), written in C++, describes all the steps as in basic implementation:
Code sources are available on our GitHub.
Entry point: CudaBasedGameApplication.java.
Compared to traditional threads implementation, the performance increased by (!) 8000 times and has almost linear growth. See Table 2 for the details on the environment and Figure 8 for the performance graph.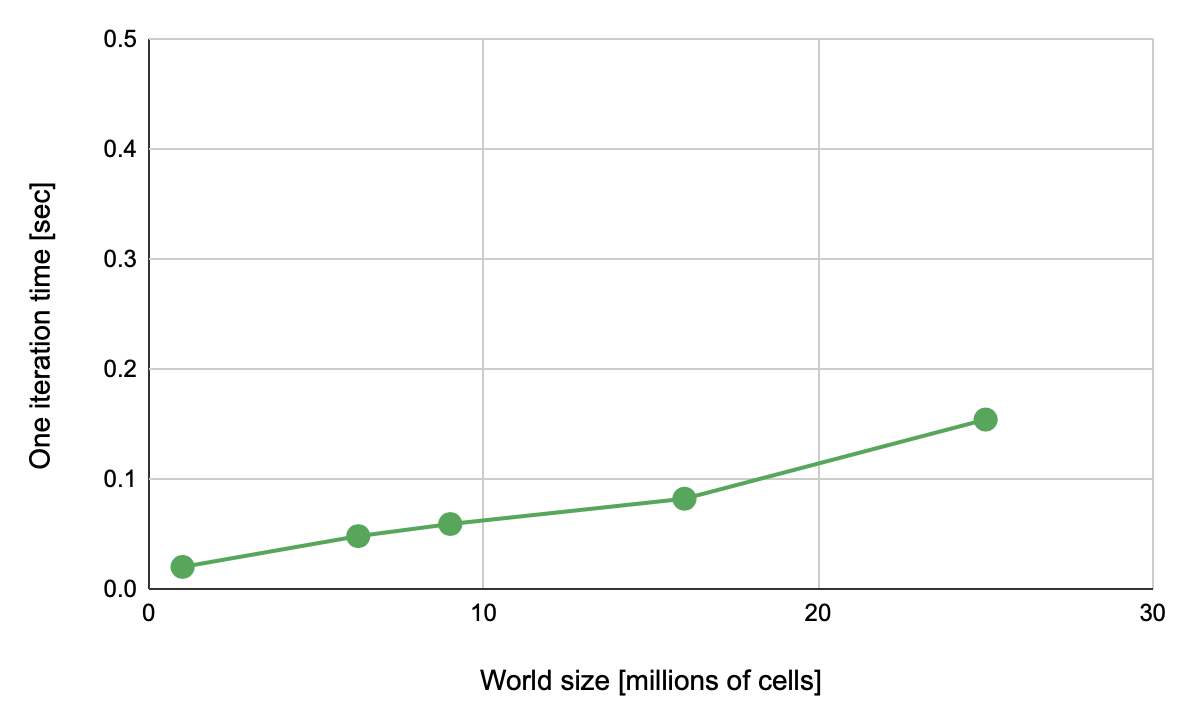 Figure 8. CUDA performance
Figure 8. CUDA performance
| CPU | 2-Core Intel Core i5-4210U@1.70GHz |
| GPU | NVIDIA GeForce 840M |
| RAM | 16GB DDR3 |
| OS | Windows 10 |
| JRE | HotSpot Runtime Environment (build 1.8.0_321-b07) |
Table 2. The environment of CUDA
Scenarios 2 and 3 with independent threads are not possible due to the nature of CUDA and GPU which is a pity because seeing chaotic Scenario 3 life development in FullHD resolution would have been spectacular.
Looks like we are missing the way to have a really huge amount of independent threads but… there will always be someone to fill the vacancy. Meet the Java Loom Project!
Project Loom is an OpenJDK project that aims to enable “easy-to-use, high-throughput lightweight concurrency and new programming models on the Java platform.” The project aims to accomplish this by adding three new constructs:
The key to all of this is virtual threads. They are managed by the Java runtime and, unlike the existing platform threads, are not one-to-one wrappers of OS threads.
Loom adds the ability to control execution, suspending and resuming it, by reifying its state not as an OS resource, but as a Java object known to the VM, and under the direct control of the Java runtime.
Whereas the OS can support up to a few thousand active threads, the Java runtime can support millions of virtual threads. Every unit of concurrency in the application domain can be represented by its own thread, making programming concurrent applications easier. Forget about thread-pools, just spawn a new thread, one per task.
Below is the environment we’ll use for all scenarios and here is the code on our GitHub (branch loom).
| CPU | 6-Core Intel Core i7@2,6 GHz |
| RAM | 16GB DDR4 |
| OS | macOS Monterey |
| JRE | OpenJDK Runtime Environment Temurin-17+35 |
Table 3. Environment Loom
Scenario 1. Almost the same as we had in the traditional Java threads case but with virtual threads instead of the traditional ones. But take a look at the performance testing results: they differ significantly.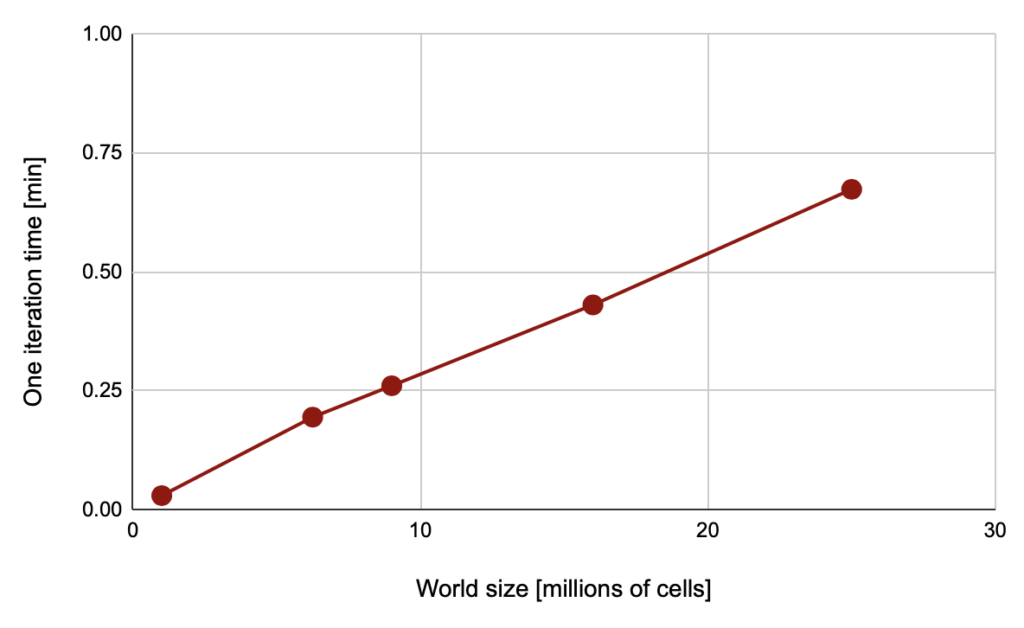 Figure 9. Virtual thread based game iteration chart
Figure 9. Virtual thread based game iteration chart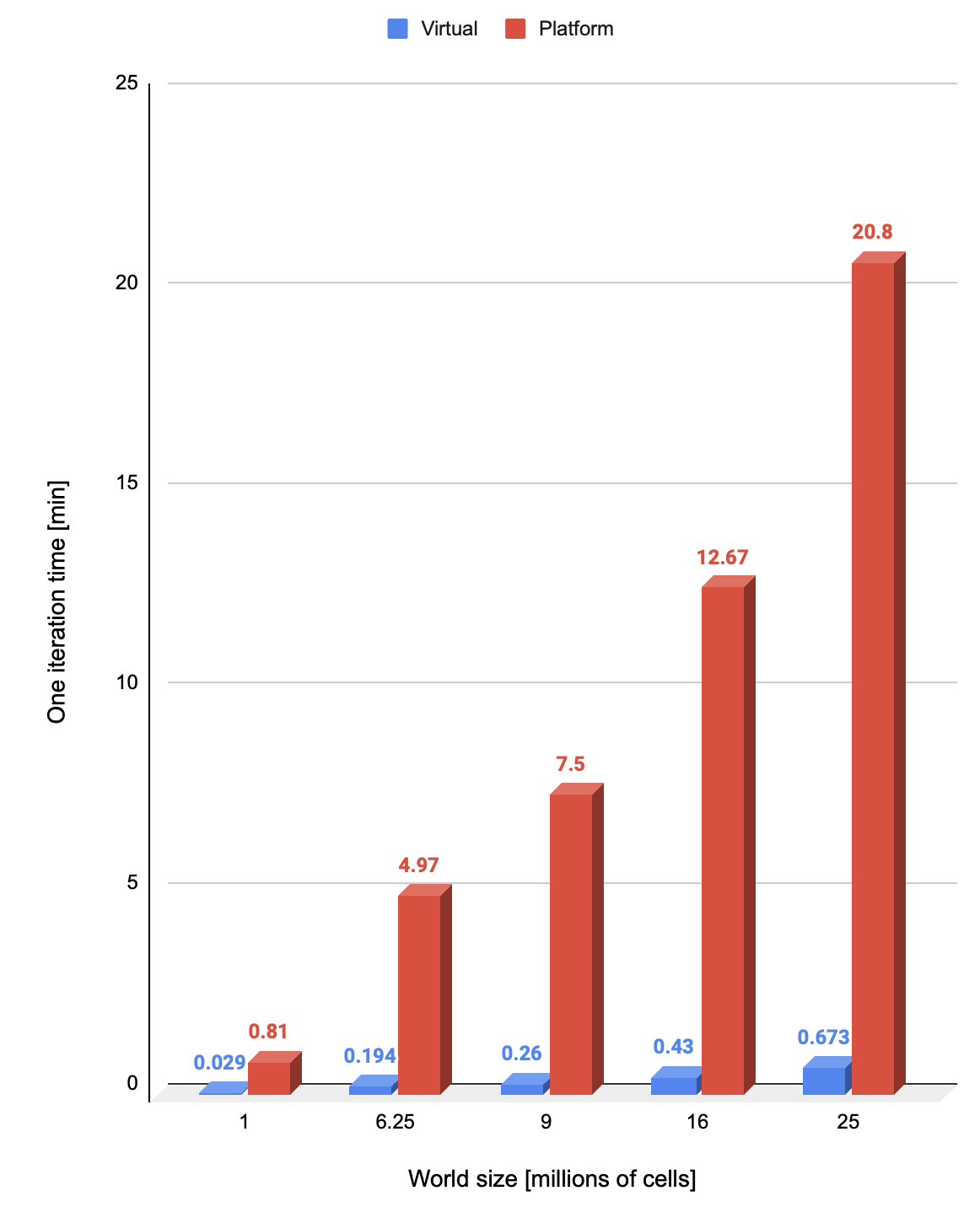 Figure 10. Game performance comparison on different types of Java threads
Figure 10. Game performance comparison on different types of Java threads
The 5000*5000 iteration lasted less than 1 minute (FYR: it took 20.8 min on Java platform threads).
The biggest heap usage – 5059.77MB.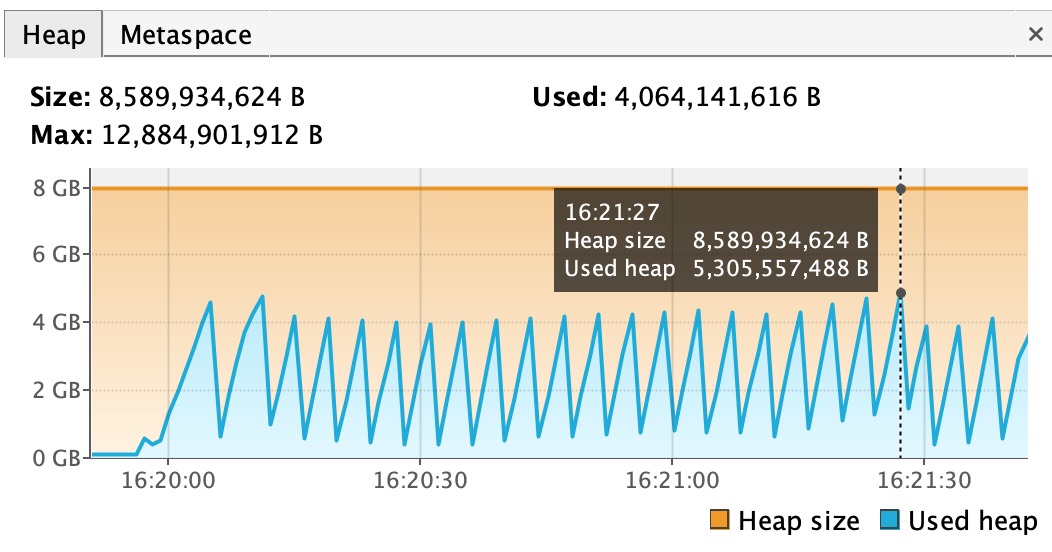 Figure 9. Heap usage of basic application on virtual threads
Figure 9. Heap usage of basic application on virtual threads
Average CPU usage – 36%.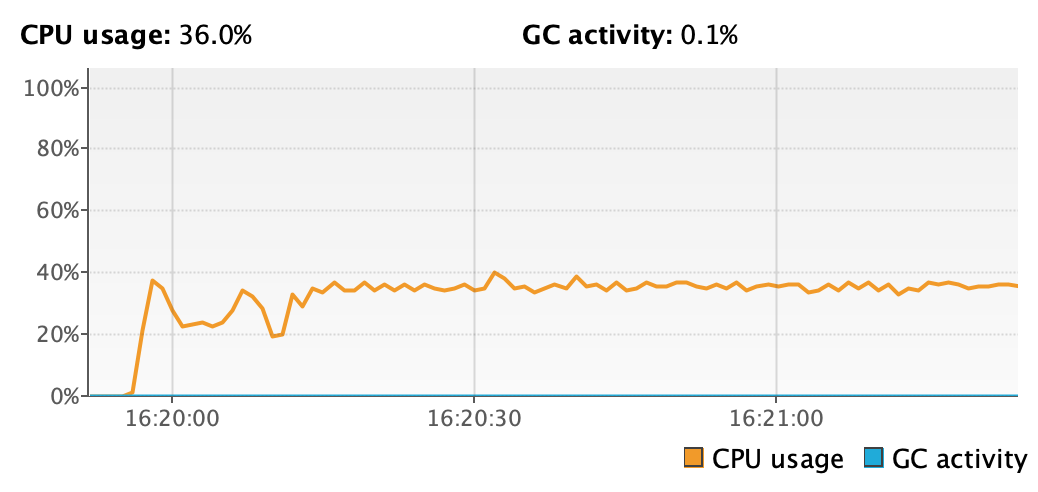 Figure 10. CPU usage of basic application on virtual threads
Figure 10. CPU usage of basic application on virtual threads
Scenario 2
As we remember, there was a 4k platform threads limitation.
Let’s try to simulate a much bigger 2500*2500 world:
Application successfully starts and runs – max. heap usage 10.62GB.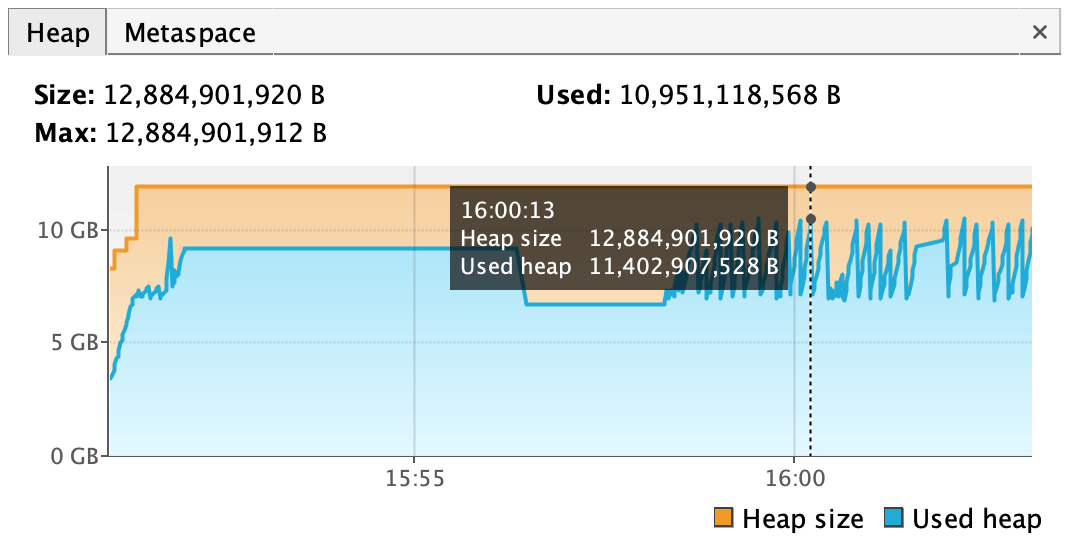 Figure 11. Heap usage of decentralized application on virtual threads
Figure 11. Heap usage of decentralized application on virtual threads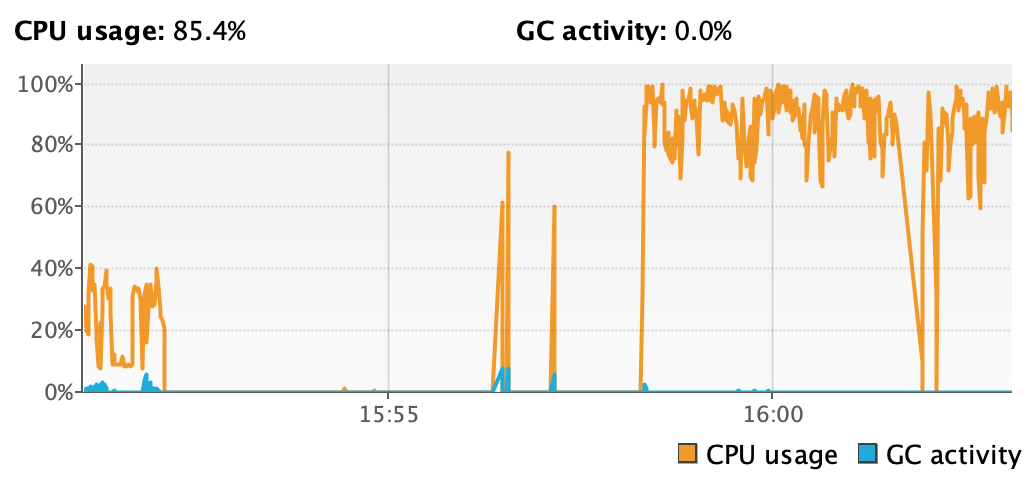 Figure 12. CPU usage of decentralized application on virtual threads
Figure 12. CPU usage of decentralized application on virtual threads
Despite requiring 6250000 virtual threads, there is one fork join pool with 12 carrier threads (see Figure 13).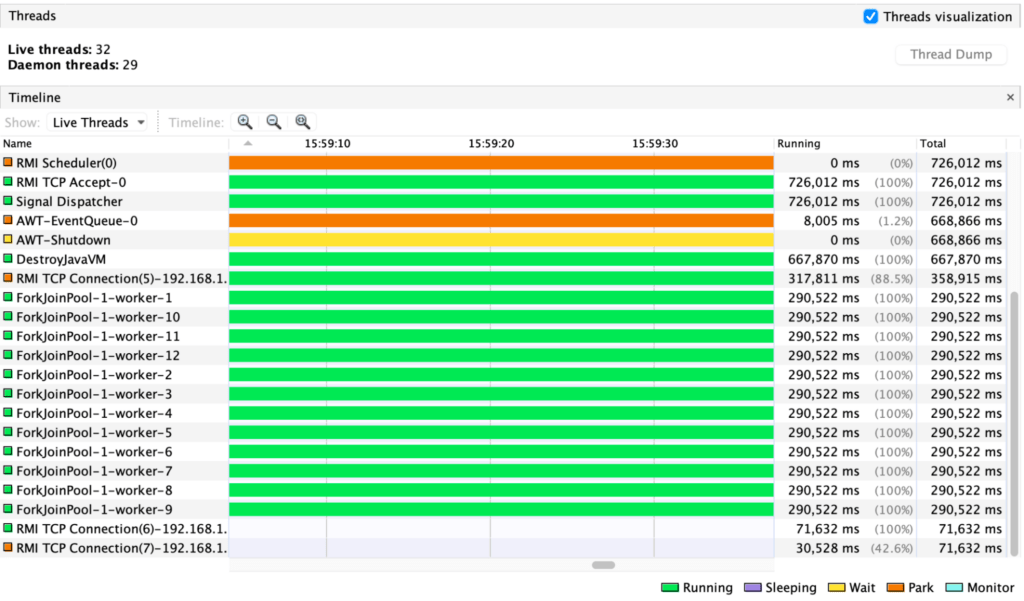 Figure 13. Threads visualization of Loom decentralized application
Figure 13. Threads visualization of Loom decentralized application
However, we encountered the sad outcome: starting the virtual thread doesn’t guarantee that it will begin execution at all under some circumstances. We experienced application blocking as some cell processors are forever waiting for their neighbors.
Scenario 3
In contradiction to Scenario 2, now cells are not waiting for neighbors to have the appropriate version so we made an assumption that may help all threads to finally start and execute. And we were right: the iteration finished (all threads executed) but we discovered another sad outcome – second generation of Life took significantly bigger amount of time; the third again took some extra time, and so on and so forth (See Figure 14).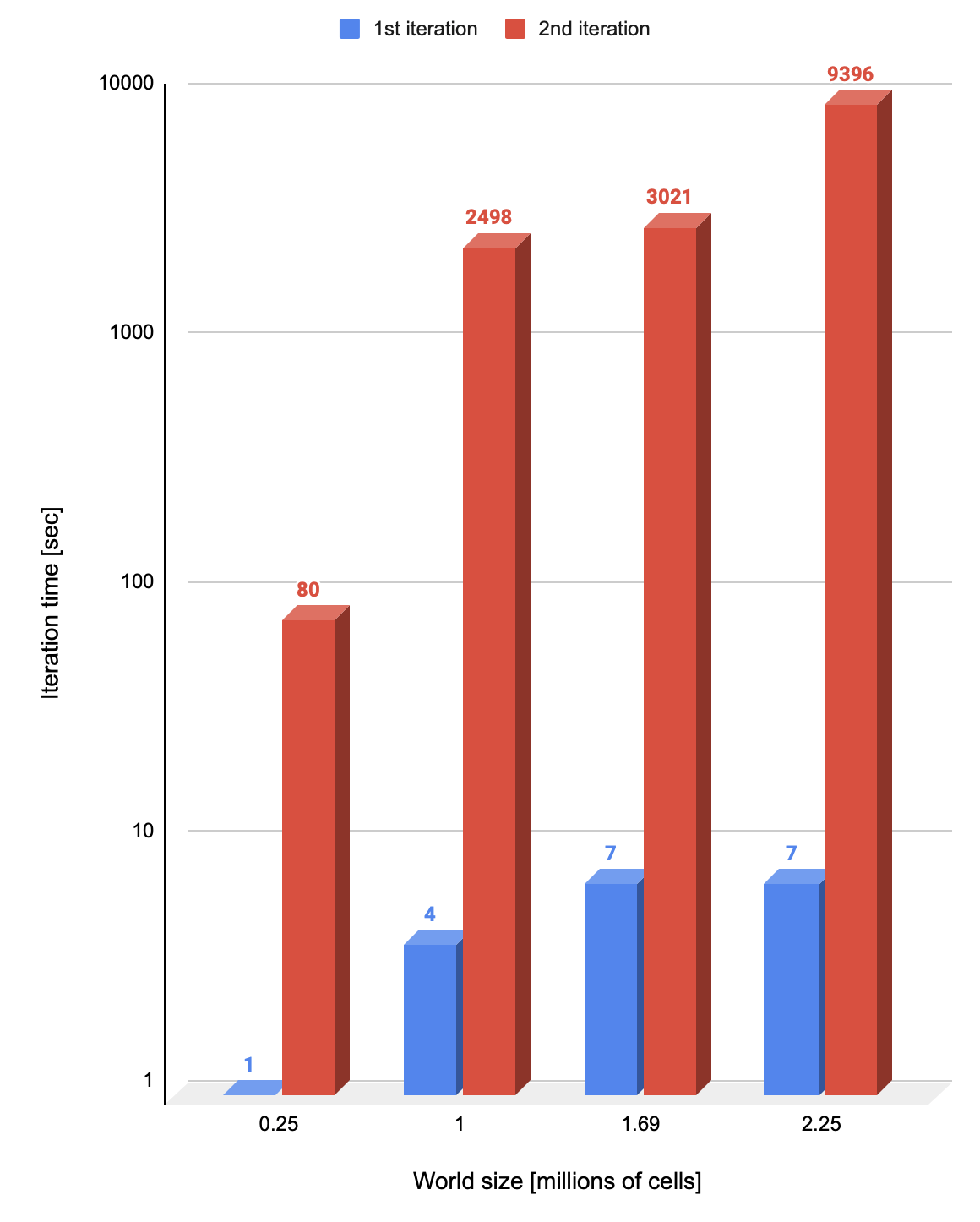 Figure 14. Game iteration performance comparison on virtual threads
Figure 14. Game iteration performance comparison on virtual threads
We started with the idea to see how Life will behave with the switched off synchronization and ended up with an interesting journey familiarizing us with CUDA and Loom and uncovering their pros and cons compared to each other and traditional threads approach.
The considered several ‘Game of Life’ algorithms allow us to clearly see the main pros and cons of parallel computing on the CPU and GPU, as well as on an existing JVM platform and future virtual threads.
It is necessary to distinguish algorithm performance comparison as:
| Platform | Virtual | |
|---|---|---|
| System stability | stable | unstable* |
| Simultaneous threads | defined limit | undefined limit |
| Parallel execution | slower | faster |
| Size | heavyweight | lightweight |
* in case of concurrent self organized live simultaneous threads:
– some threads may not start
– waiting threads become available after a huge delay.

Learn about the most critical aspects of customer engagement and how to build and implement a reliable strategy for long-term success.
Ready to innovate your business?
We are! Let’s kick-off our journey to success!





