
End of Support for Microsoft Products: What You Need to Know
Stay informed about the end of support for Microsoft Office 2016 & 2019, Exchange Server 2016 & 2019, and Windows 10.

While AI models have the capability to generate virtually any image in various styles, they still struggle with accurately depicting the seemingly ’simple’ human hand.
We have reached a point where AI can create compelling texts, outsmart professional players at board games, write decent software code, generate stunning images in various styles, and even simulate protein folding. And yet, it still struggles to draw human hands that don’t look weird.
Why is that? Why do powerful models like Dall-E 2, Midjourney, and Stable Diffusion fail at such a seemingly easy task? The short answer is that it’s not actually that easy; it just appears that way from our human perspective. This article will delve into the specific reasons for this ’flaw.’
Let’s begin by briefly recapping the types of machine model architectures commonly used for image generation (Figure 1.)
First, we have Variational Autoencoders (VAEs). They compress inputs into a low-dimensional space and then reconstruct them during training. Subsequently, the latent space is sampled to generate new data. The advantage of these models is that they are relatively easy to train, but their outputs tend to be blurry and of low quality.
Another type is Generative Adversarial Networks (GANs). These architectures can quickly produce realistic images, but due to the adversarial nature of their training, they are susceptible to issues like mode collapse and vanishing gradients. As a result, GANs face challenges with instability and an extremely difficult training phase.
Diffusion models are currently the ones used most commonly for image synthesis. Starting with GLIDE, they have essentially replaced GANs, Variational Autoencoders, and other deep generative architectures. They offer improved output stability, predictability, sample quality, and diversity. Additionally, unlike other models, diffusion models allow for textual guidance. Figure 1. Types of generative models
Figure 1. Types of generative models
As discussed in this article (and also mentioned here), diffusion models function by gradually introducing noise to the input and then running the process in reverse to restore the original image. One downside is that its denoising process is sequential, resulting in a slower generation pace compared to that of VAEs and GANs. However, since these algorithms are relatively new, they will likely undergo multiple architectural improvements and modifications in the near future, and the aforementioned challenge will no doubt be addressed.
Despite the differences in structure, topology, and effectiveness among these three types of models, the common thread is that they all need to learn data distribution to generate new data. For images, this means that each time they are tasked with producing an image, the model must draw upon related images from its ’memory’ and strive to replicate the learned patterns.
Learn more about how we enhanced Ayasdi’s innovative and advanced Machine Learning platform. Success story
One of the reasons lies in the inherent complexity of the human hand. It comprises multiple elements of varying shapes and sizes, and its structure is incredibly intricate, even though we as humans may take it for granted. Fingers, palms, joints, tendons, and other components are all interconnected and arranged in a specific manner. To draw hands realistically, the model must learn the vast array of natural variations in the hand’s parts and understand, like humans do, the spatial relationships between these elements. However, it’s important to remember that AI can only learn patterns; it cannot really comprehend things.
In addition, to capture the articulation and deformations that occur during hand movements, algorithms need to understand how joints function and the range of motion each of them enables. The human hand possesses a wide range of articulation, further complicating the task. We can perform subtle finger movements, rotate our hands, assume complex poses, make fists, and much much more. Therefore, realistically modeling the dynamic nature of a hand is an exceptionally demanding task.
Another factor is the variability of hands from person to person. Different individuals have varying hand proportions, sizes, and even shapes. An immense dataset would be required to teach a model how to generalize and create a realistic representation of each hand type. Further compounding this issue is the fact that hands in freely available images on the web are often obscured or appear different depending upon the angle.
For example, in the provided image (Figure 2.), the person is making a ’pointing’ gesture, and a large portion of their palm and a few fingers are not even visible.
Figure 2. The pointing gesture
To a machine that cannot derive an underlying structure and is unaware that there should be exactly five fingers, this appears as a version of a complete hand because the picture isn’t labeled “A hand is making a pointing gesture with the index finger visible, pointing outward, while the palm and the rest of the fingers are almost entirely obscured.” Consequently, it may later attempt to recreate this pattern and combine it with other incomplete cues from similar photos, resulting in something nightmarish.
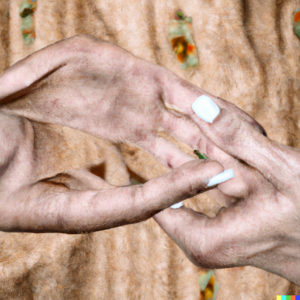

Figure 3. Dall-E 2 and Stable Diffusion outputs, when prompted with “a person holding a banana.”
This issue doesn’t arise as much with human face generation because there are not many internet images where it is unclear that a person has two eyes, one nose, two eyebrows, lips, and one forehead, even in low-light portraits. Thus, the algorithms do not entertain the idea that three lips, an eye in the center of the face, and half a nose or some similar deformation is acceptable.
Moreover, since facial features do not move and have relatively similar proportions across individuals, the algorithm will not learn to place a nose on a cheek or an eye where the mouth should be. In contrast, hands exhibit a vast amount of variability in terms of shapes and sizes, and movements make them look completely different, which is why it is nearly impossible to discern strict patterns.
Additionally, the tolerance for error in hand images is very low. While a nose can be larger or smaller compared to the eyes, and even a difference in size between the left and right eye may not seem unnatural, having a thumb and little finger longer than the index, middle, and ring fingers is clearly abnormal. And even beyond that, there is a lack of sufficient hand data (at least this was the case when most popular models were trained) due to the general absence of hand pictures, especially in various poses, on platforms like Instagram and the web in general.
Annotating a large-scale hand dataset, given the number and variability of attributes, is a time and resource-intensive task that requires labeling all the joints, finger positions, and hand poses. Collecting this data is very challenging as people do not organically post a lot of hand pictures, and there are potential ethical and privacy concerns, as someone’s fingertips contain sensitive biometric information that could be misused. Ensuring consistent image quality for such a dataset would also require large-scale quality control measures such as outlier removal, noise reduction, and filtering.
Specialized equipment and expertise would also be needed for hand motion capturing. And, the researchers would need to conduct the procedures in a controlled environment which poses even more challenges in terms of recruiting participants for studies, and setting up and managing the necessary infrastructure.
Lastly, the dataset must encompass images from diverse ethnicities, age groups, demographics, and even occupations (if there’s also a goal to show the types of hands typically seen in different professions, such as piano players versus mechanics).
The reasons behind poorly generated AI hands are multifaceted. They include the low margin of error we allow for hand representations, the immense variability of possible hand movements that algorithms must be aware of, and the lack of readily available relevant data for training.
That being said, researchers have recently shifted their focus toward addressing this issue. The latest version of Midjourney, for example, has already made significant progress in this area. In the rapidly evolving field of AI, advancements occur at lightning speed, and we anticipate that the problem of faulty representation of the human anatomy, including teeth, abs, ribs, and other complex anatomical structures, will be resolved soon.
If you would like to learn more about the performance of various generative models and their potential to drive enterprise value, feel free to contact our experts right now.

Stay informed about the end of support for Microsoft Office 2016 & 2019, Exchange Server 2016 & 2019, and Windows 10.
Ready to innovate your business?
We are! Let’s kick-off our journey to success!






