Artificial intelligence (AI) running our businesses
Artificial Intelligence is a big success. It’s one of the fastest growing areas of IT for all businesses. The hyper automation mega trend is that of increasingly more processes which are expected to be performed with minimal human intervention and supervision.
AI is expected to make more and more autonomous decisions. Often they are faster and better optimized than those made by humans. Sometimes they fail and of course we want to know WHY.
Automated machines, including medical devices, power grids, modern engines, automated cars, planes, spaceships, weapons and other critical applications demand more explainability from AI solutions.
→ More about Meeting the Future. Trends & Technology 2021.
The prevailing approach now seems to be to not care as long as it works, and then to be surprised when it suddenly does not. The options for debugging then are very limited, like trying to guess the reason why and experimenting with new model parameters and data. The risk is that the new model may be even less predictable than the old one.
So if there’s a very low percentage of wrong cases, the decision is often not to touch it all and to keep your fingers crossed for the future.
With a growing dependence on Artificial Intelligence this sounds scary and irresponsible, but surprisingly this is how many models are deployed in production nowadays. It applies especially to prepackaged ready-to-use AutoML and similar models that are targeted at ML users and not serious data scientists. However, it’s an unfair myth that cloud based models, used after just a few hours of online training, are the only examples of unexplainable AI problems.
In fact, even the very creators of the AI frameworks and engines often don’t know how the models will behave in different situations and contexts. It’s not something they are eager to share about, but from time to time they confess that they in fact have lost control over their children of creation. Of course, there are tests on large datasets and they pass them, but real world data never stops surprising and breaking the models.
For example, cars that have driven millions of miles on their own, suddenly crash and we don’t really know why. (source: DARPA)
(source: DARPA)
What does it mean for business?
The consequences of not being able to control AI based solutions will soon get worse than “just” losing the trust of the clients and market share. New regulations in the EU, for instance, will make AI creators and operators legally responsible for the consequences. Similarly to what happened to video streaming companies and the content they deliver, nobody will ever be able to say again, ‘it’s not our fault nor our responsibility’.
We should not humanize machine learning (ML) anymore as it’s just another technology, and not a being of any kind. The people who use it for their business purposes cannot hide behind the myths and hypes.
For example, some clients have positive decisions made by AI about their loan, some don’t. Those who were refused want to know “why?”. Except for the obvious cases which can be explained by humans just looking at the base data, it is very difficult to do.
Even when it is possible, the explanation can be barely usable for data scientists, but totally understandable by humans (for instance the value of parameter a8362 is less than threshold 0.74734). We cannot simply apply human logic as AI has a totally different logic. One could say that traditional software represents an almost classical logic known by humans, while advanced machine learning (ML) follows a different logic and often with unknown rules.
Explainable AI (XAI) for the creators
Those who are curious about how (and when) their models work are the models’ creators, machine learning (ML) experts and engineers. For them explainability can be provided in a raw mathematical form, and they want as much data as possible to be able to improve their models.
There’s a lot of talk about applying software engineering practices to machine learning (ML). What about debugging? With traditional software engineering there are assertions, breakpoints, monitors and logs, that control how the software flows and detects the root cause of the bug. It’s not easy, but finally there are mature practices and tools to do this effectively.
In the case of Machine Learning (ML), there’s no simple equivalent of debugging, especially in the case of more advanced techniques, such as neural networks. It’s more about experimentation with the black box that … was just created.
Explainable AI (XAI) for business users
Customers also want to know why.
Why was the loan decision negative? Why do autonomous cars decide to stop in the middle of nowhere for no apparent reason? Why is my face no longer recognized by my phone after changing my hair color or while wearing glasses?
This is even more complex. We would like to know what we can do to help ourselves, what to do to get a loan, and which behavior or data caused a negative decision?
The first problem is, no matter whether with AI or without AI, that mathematical models, even those traditional in the risk areas (insurance, finance, heath), are already very complex and there are only a few people who understand them; and many are not able to understand them at all.
The second is the nature of advanced AI, which is unexplainable by default. In fact, even the mathematical foundations of how it works and the why of how it works are not well understood.
What can we do about it? 
Explainable by default
Highly regulated industries such as banking, insurance and pharma require the highest levels of explainability.
→ Explore Artificial Intelligence & Machine Learning in Finance: the Whys, the Hows and the Use Cases
In many cases data scientists prefer to use traditional data analysis techniques such as linear regression, decision trees, rules engines and others.
They are still improving and if used properly they can help achieve acceptable results with very good explainability.
Restraint is needed to resist the temptation of using the latest ML technologies. Only experienced data scientists can choose the best set of tools and techniques to achieve the best business results.
The drawback of this approach is potentially much less performance and accuracy. Some problems cannot be solved using traditional methods at all. Rarely is it too high a price to pay for explainability.
Experimentation with a black box
More complex models with advanced neural networks often generate much better results in terms of accuracy and much faster than more traditional methods.
For instance, trying to implement facial recognition on smartphones without using those modern advanced methods simply wouldn’t be possible. It was absolutely out of reach of the traditional pattern recognition techniques. With high accuracy, we can forgive this from time to time when it fails, especially when it’s more than 99.9% accurate.
But, there are applications when we must know exactly how and when it works. Just hoping for good results is not an option.
A 1% failure rate for facial recognition on the phone is excellent, but 1% for more critical applications, such as autonomous vehicles or planes, is simply unacceptable for safety reasons; one in a hundred flights would end up in crashes and loss of human life.
→Learn why Essentially, Data is good. It’s the use cases that can be problematic
Fortunately there’s a new family of methods to deal with this problem.
A new approach assumes that we treat the machine learning model as a black box and experiment with different input samples to learn about its behavior. The more we know about how it responds to different input values, the more predictable it will be.
It’s kind of ironic that by designing, training and tuning the model, we create something that gets out of our control and then we treat it as a black box. But, this approach seems to be the best way for the most advanced models right now.
It requires thousands of tests performed with different sets of data, and then gathering the results which requires new pipelines and methods borrowed from software engineering.
→ Learn more about Continuous Delivery for Machine Learning (CD4ML)
Another technique that is helping with this is the artificial generation of behaviors and data. Gathering real world data and labelling it is very expensive, and computers can do it much faster.
For instance, recognizing people crossing the streets in different environments and weather conditions is often done by using simulated gaming environments and artificial cameras capturing images of the scene.
So in other words AI is checking on other AI to see if it works better.
→ Read more about Generative AI – creative AI of the future
But we can easily recognize if the input is correct (like generated scenes or financial data), as it’s still within the reach of data scientists and their tools. We can also verify outputs with relatively high accuracy (albeit lower than inputs). For example, will the car stop given this image of the scene, some will reply that obviously yes, and some reply maybe not.
So, we do have options to deal with the problem of explainability. Great! Great, but not that great, all of those techniques require tons of processing, petabytes of data, billions of CPU hours, all of which has already started to be a problem. One is the price and availability of such computing power because it’s thousands and millions of dollars/EUR. Another is the electrical energy consumption, some measure it in tons of uranium for nuclear reactors.
Future of XAI
Someone compared future programming to training digital pets; by showing them many examples,they will discover our intent and learn. It is time consuming, resources consuming and frustrating. It’s a little bit of what ML looks like today. And, it’s not acceptable in the long run.
The expectation of the industry is to have it all ASAP: sophisticated, fast, and agile models with a high degree of explainability. The best of both worlds should be available to all the organizations, profit andnon-profit, in order to truly embrace the AI-driven future of computing.
In fact, this is the mission statement of DARPA (Defense Advanced Research Projects Agency) and other AI focused organizations. 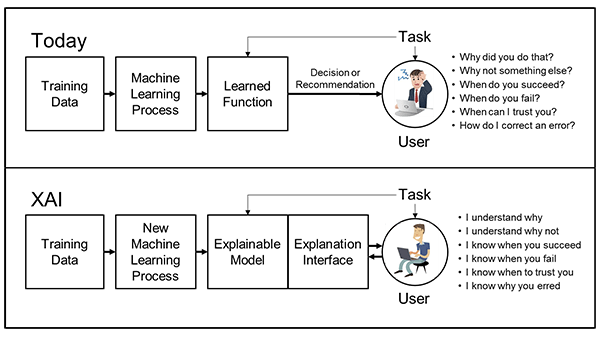 (source: DARPA)
(source: DARPA)
Responsible AI (RAI) is the next level and the goal, which is based on explainable AI and takes into account business ethics and the growing number of regulations. The businesses who benefit from AI don’t want the biases or discrimination that base everything on the data from the past. A new generation of algorithms will be more advanced and better trained to avoid known issues with current technologies, and to enable XAI and RAI.
→ Discover our take on Strategic Sustainability: What’s inside the box?
With our growing dependence on AI and ML in particular, we should demand more control and explainability . . . today.
Our data science team understands this and can help you deliver great AI solutions with the required degree of explainability.









