Intro
Data is the fuel for the modern digital enterprise, however it is much harder to get it in good quantity and quality than many have anticipated.
The most visible and most talked about problem is data quality. Only the modern end to end approach allows companies to achieve the best results.
→ Read more about Data quality at the source pattern – what???
Even when all the data sources are conforming to high standards and data processing jobs are designed, implemented and maintained well, there’s another problem that needs to be addressed.
Isn’t data quality itself hard enough?
The problem is, how do we know what is really happening with all the data in the organization from the sources to the consumers.
In other words, we should not only focus on the nodes of data processing but be able to have a holistic view of the data transformations and their data flow within the entire organization.
Does it sound like something nice to have but not really something enterprises need?
What is data lineage about?
Data is moving from the source when it is created for multiple consumers. Very often it means multiple steps, processing nodes, and jobs where the data is being processed, transformed, filtered and merged with other data.
Tracking data flow and transformations
At each step of the processing, it is beneficial to know what the source of data is, what is its schema, who owns the data, what the lifecycle of the data is, how fresh the data is and who the users of the data are.
Tracking this information in an organized, structured and predictable manner is called data lineage.
It’s worth noting here that there’s no clear, single, or standardized definition of data lineage. There are concepts which are similar, such as data flow, data chain, and data integration. In some parts they overlap, but data lineage is focused on the pathway and alterations to the data along it.
Business users
Data lineage helps business users discover dependencies within the data. It is important to perform a ‘what-if’ analysis to find the real relationship between the different data and its sources.
It might sound too technical but it really is not, because business users operate on higher level abstractions and business models of data, and not their physical representation such as database tables, JSON documents, etc.
Data lineage helps to reduce the risks related to sensitive data (i.e. personal data, GDPR). It enables the tracking of what is going on with it, in the further steps of processing. In case of a change in a data protection policy, as a result of new international or national regulations as well as local company policy changes, it allows businesses to analyze the impact of the new legislation on the organization. It helps to identify the pain points and the number of modifications required to align with the new data protection rules.
And yes, new regulations are coming for improved privacy, then probably for ethical AI.
Regulatory documents rarely mention data lineage, and it’s a kind of a pity, as it would popularize the idea among enterprises and allow for a faster and easier adoption of any new legislative rules for data processing.
Business changes in organizations and markets take place all the time. What is important, from a data perspective, is the impact of the change on the analysis. Data lineage makes it easier to assess the change and perform root cause analysis. For instance, it allows for finding a new way to generate the data required, within the new process and based on the knowledge of current data flows. So in other words, it speeds up the change process.
Data quality and management initiatives can also be helped by data lineage. Both business and IT are much more aware of what is happening with their data from both perspectives.
IT users
For the technical users, data engineers for instance, it allows them to track the data flow and transformations of data in order to pinpoint the location of bugs and data corruption. It helps to answer the question “Why?” (i.e., why errors, why data loss, why this data dependency across different data sources, or why sudden drop in data quality).
→ Explore why Essentially, Data is good. It’s the use cases that can be problematic
Please keep in mind that dataset schema versions change over time, so data lineage tracing has also to take it into account.
More than metadata
Metadata describes the structure and meaning of the data. Proper metadata management is a cornerstone of any serious data governance strategy.
Doing this properly is a challenge in itself for tracking metadata changes. But even more importantly, it may not be enough. It’s the dynamics of the data values that are also very important.
Adoption of data lineage
Data lineage is the lesser known part of the data governance strategy.
From the IT perspective, it’s another service operating on metadata with specific APIs, administrative activities and deployment requirements.
Some examples of open source tools are: Apache Marquez, Talend, Apatar, CloverETL, Kylo, Dremio, Jaspersoft ETL and Octopai.
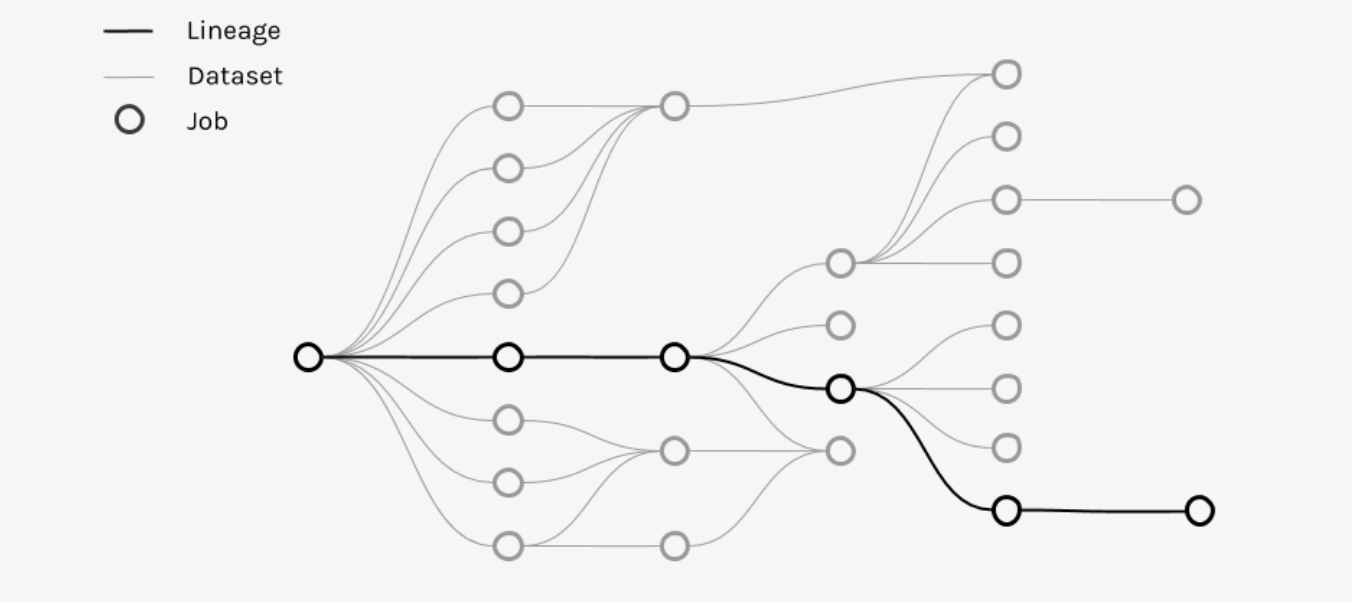
The following graph shows the data lineage from the data source to the data consumer after multiple jobs were performed on the data. Data lineage is usually represented visually to enable humans to more easily track the changes and processing characteristics.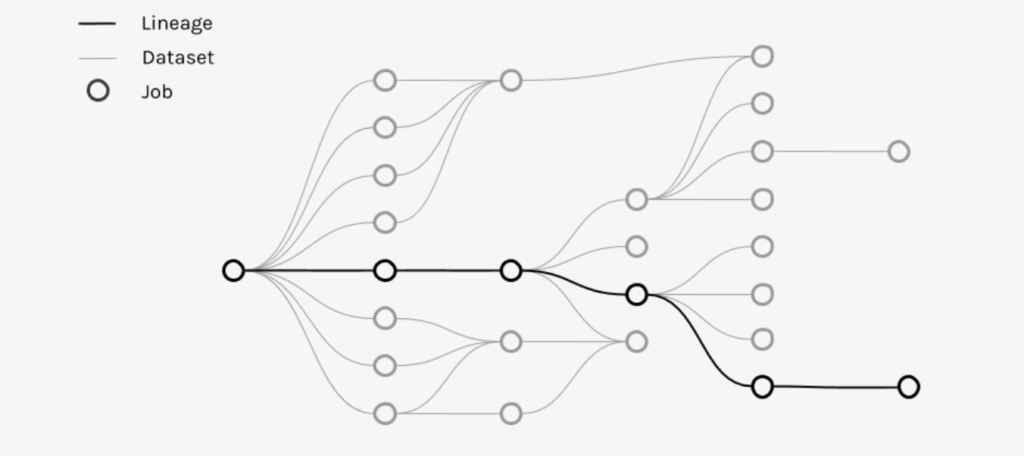 (source: https://marquezproject.github.io/ )
(source: https://marquezproject.github.io/ )
Metadata is collected at each step by connecting data transformation nodes with a data lineage tool. Datasets are registered in the repository with their schemas, so are jobs with their inputs and outputs. Task-level metadata collection is then applied to every job and data in order to be able to track the data lineage.
It is recommended that data lineage tracking should be a key feature of data processing orchestrators, such as Apache Airflow and commercial products.
Data lineage projects have to answer the questions of feasible scope, method of description, and decision, if data lineage is to be focused on metadata management or on data values.
Future of data lineage
Data lineage used to be a very abstract concept, but now it has adapted and is proving its usability for both business and IT.
In the beginning of data lineage, the lineage descriptions were often kept in spreadsheets and updated manually by users. Now, there’s a new family of tools and patterns to do this in a much more scalable and collaborative way.
The modern data lineage tools are focused on real-time data lineage, with the ability to visualise and react in the real time.
Of course, because of the need for efficiency, data lineage descriptions and management is more and more often automated, including machine learning tools to discover patterns in the data so as to create metadata and trends. It also helps with updating the data lineage information. The entry barrier is high, but the investments will return and help in the future. Leaders understand that there will be further changes in the business model and regulations, and thus prepare their organizations for that.
The future is in the data engineering culture, and DataOps will deal with more advancements in data management and processing. Data lineage fits very well into the modern image of data processing.
→Read more about DataOps – more than DevOps for data
Avenga’s data offer ranges from data governance strategy to actual implementations of the strategic and operational solutions using cloud and on-premise technologies.