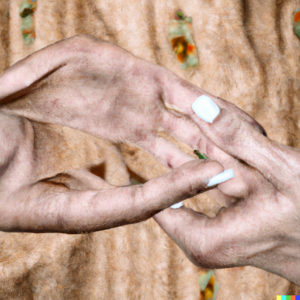
While AI models have the capability to generate virtually any image in various styles, they still struggle with accurately depicting the seemingly ’simple’ human hand.
We have reached a point where AI can create compelling texts, outsmart professional players at board games, write decent software code, generate stunning images in various styles, and even simulate protein folding. And yet, it still struggles to draw human hands that don’t look weird.
Why is that? Why do powerful models like Dall-E 2, Midjourney, and Stable Diffusion fail at such a seemingly easy task? The short answer is that it’s not actually that easy; it just appears that way from our human perspective. This article will delve into the specific reasons for this ’flaw.’
Types of Generative Models Used for Image Creation
Let’s begin by briefly recapping the types of machine model architectures commonly used for image generation (Figure 1.)
First, we have Variational Autoencoders (VAEs). They compress inputs into a low-dimensional space and then reconstruct them during training. Subsequently, the latent space is sampled to generate new data. The advantage of these models is that they are relatively easy to train, but their outputs tend to be blurry and of low quality.
Another type is Generative Adversarial Networks (GANs). These architectures can quickly produce realistic images, but due to the adversarial nature of their training, they are susceptible to issues like mode collapse and vanishing gradients. As a result, GANs face challenges with instability and an extremely difficult training phase.
Diffusion models are currently the ones used most commonly for image synthesis. Starting with GLIDE, they have essentially replaced GANs, Variational Autoencoders, and other deep generative architectures. They offer improved output stability, predictability, sample quality, and diversity. Additionally, unlike other models, diffusion models allow for textual guidance. Figure 1. Types of generative models
Figure 1. Types of generative models
As discussed in this article (and also mentioned here), diffusion models function by gradually introducing noise to the input and then running the process in reverse to restore the original image. One downside is that its denoising process is sequential, resulting in a slower generation pace compared to that of VAEs and GANs. However, since these algorithms are relatively new, they will likely undergo multiple architectural improvements and modifications in the near future, and the aforementioned challenge will no doubt be addressed.
Despite the differences in structure, topology, and effectiveness among these three types of models, the common thread is that they all need to learn data distribution to generate new data. For images, this means that each time they are tasked with producing an image, the model must draw upon related images from its ’memory’ and strive to replicate the learned patterns.