
How to choose the best cloud platform for AI
Explore a strategy that shows you how to choose a cloud platform for your AI goals. Use Avenga’s Cloud Companion to speed up your decision-making.

Generative models are massive. Their popularity began to rise with GANs (Generative Adversarial Networks), which are widely applied in computer vision (image and video processing, generation, and prediction), as well as in various science and business-related fields, such as crystal structure synthesis, protein engineering, and remote sensing image dehazing. And now, as GANs are being replaced with more computationally efficient diffusion models, the use of generative algorithms has skyrocketed even further.
We’ve already touched on diffusion networks in this blog post, but haven’t yet fully explored their inner workings. In this article, we’ll shed some light on how GANs, image, and movie diffusion algorithms function and talk about their evolution. We created this image using Stable Diffusion
We created this image using Stable Diffusion
By now, even non-tech-savvy people have heard of things like DALL-E, Stable Diffusion, and Imagen. Many have played around with their free prototype versions on the web, but few understand, even on the basic level, how these models do what they do.
Inside, generative algorithms are quite complex with many different moving parts, even though they might not seem complicated in functionality. Let’s review them one by one.
A GAN consists of two elements – a generator and a discriminator. The first submodel creates realistic ’inputs’ and submits them to the second one, whose job is to determine their validity. During training, the generator iteratively improves itself to produce better fakes. The discriminator, however, also changes its parameters to become better at spotting them. It’s a zero-sum game.
Eventually, the generator learns to create data objects that are convincing enough even for the most advanced forms of the discriminator. And of course at that point, it can easily fool the human eye. Figure 1. Realistic face generated by StyleGAN2
Figure 1. Realistic face generated by StyleGAN2
Video prediction is one of the most exciting applications of GANs. By analyzing past frames, the network can predict what will happen in the immediate future, which has significant implications for modern surveillance systems and predictive maintenance platforms. GANs can also be used for image enhancement, inspecting individual pixels and upscaling them all in order to generate better-resolution pictures.
However, GANs also have significant downsides. They are incredibly difficult and expensive to train and they can also suffer from mode collapse, in which the network repeatedly generates the same image. Finally, the overall approach that relies on converting complete noise into high-quality and high-resolution data objects is fundamentally flawed, as it often results in oddities and errors in the final output.
Diffusion models address these issues by simplifying the generation process and breaking it down into smaller, repeatable phases. Here’s how it works.
We give the network an image and have it gradually add Gaussian noise. More specifically, we create a Markov chain of timesteps where the image goes from being pure on t=0 to being completely unrecognizable (total noise) at t=T, the final step. The number T and the noising schedule must be determined beforehand. It could be a hundred, a few hundred, or even a thousand steps.
Then, we make the algorithm undo this process, giving it noise and asking it to recover the image. The unique thing is that we don’t go from t=T (final step) to t=0 (first step) in one go, as we’d do with a GAN, but, instead, we teach the algorithm to turn a noisy image into a slightly less noisy one by sliding from t to t-1, while carefully learning the transitions. After the training, the network can turn any randomly sampled noise into a cohesive image. Figure 2. The noising-denoising process
Figure 2. The noising-denoising process
Diffusion models (DM) have a peculiar denoising approach. When carrying out the processing, they estimate all the noise present on a current time step, give a rough prediction of the entire image, and then add a bunch of the noise back in to continue this loop again in the next step. This ensures stability. The DM predicts the target output multiple times from successively less-noisy starting points, which allows it to correct itself and improve upon previous estimations as it progresses.
To make the process of image generation guided, we must first convert textual data into vector representations. This is typically done with a GPT-style language model. The embeddings it produces are added to the visual input and fed to the DM. Also, since diffusion models are mostly U-net architectures, we make their cross-attention layers ‘”attend” to each text token produced by the transformer.
But, that’s not all. We also use something known as classifier-free guidance to propagate the prompt further into the model. At each denoising step, we have the network produce two outputs: one with and one without access to the text. Then we compute the difference between the results, amplify it and feed it back, thus ensuring the algorithm sticks to the direction of a prompt.
After the huge splash DALL-E 2 made, it’s being overtaken by Stable Diffusion (SD), primarily because of SD’s availability. While the former is hidden behind an API, Stable Diffusion’s code can be downloaded and tweaked to suit specific requirements. It is also much lighter in terms of computing needs.
Being from OpenAI, DALL-E 2 builds on many concepts and technologies that the firm had previously developed. For instance, it uses CLIP embeddings which convert text tokens into numbers.
The CLIP network is specifically trained on visual and text data pairs. Without delving into the math, let’s just say it learns to put the vector embeddings of an image and the corresponding caption close to each other in some space while ensuring a sizeable distance between unrelated pics and texts.
Diffusion models struggle to process large images, so they only work with small, typically 64×64 inputs, and then use upscaling mechanisms to get to the desired resolution. Both DALL-E and Google’s Imagen rely on this principle.
Stable Diffusion, however, has its own trick to deal with high-dimensionality. Instead of working with images, its autoencoder element turns them into low-dimension representations. There’s still noise, timesteps, and prompts, but all the U-Net’s processing is done in a compressed latent space. Afterward, a decoder expands the representation back into a picture of the needed size.
The video models build upon the concepts introduced in image diffusion. This is perhaps the most evident in MetaAI’s Make-a-Video. The general idea is to take a trained diffusion model, which already knows how to associate text with video, and equip it with a set of video processing tools. The training here can be performed on unlabeled data. The algorithm can eat random videos from the web and learn realistic motion. The components of the network include:
The Make-a-Video network training is highly complicated since different network elements are trained on different data. The prior and spatial super-resolution components are trained exclusively on pictures. The text-to-image diffusion model utilizes text-image data pairs, and the added video-specific convolution and attention layers are shown unlabeled videos.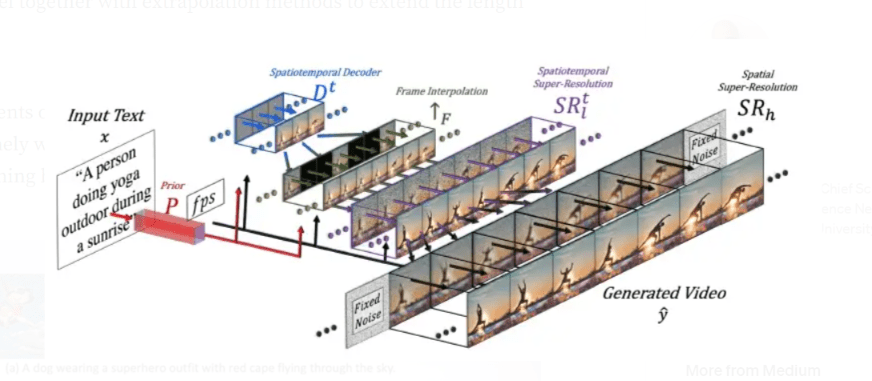 Figure 3. Make-a-video architecture
Figure 3. Make-a-video architecture
The architectural differences between these two major models are not significant. In Imagen, the CLIP encoder and prior network are replaced with the T5-XXL transformer, which is trained on text only, unlike CLIP. The base diffusion model is also enhanced with additional convolution and attention layers, but its training is slightly different as it is shown both image and video data simultaneously, and the model treats images as single-frame videos. This means video descriptions, which are hard to come by on the web, must also have been used and they’ve probably come from some internal Google-generated dataset. Next, we again have the supersampling network to get a higher framerate and the two SSR models. But then, Imagen goes further by adding two more upsampling models and yet another SSR.
Diffusion models produce more crisp and stable outputs than GANs. They could therefore replace adversarial networks in any task where the generation of realistic synthetic data is required.
3D modeling. Google’s DreamFusion and NVIDIA’s Magic3D create high-resolution 3D meshes with colored textures from text prompts. With unique image conditioning and prompt-based editing capabilities, they can be used in video game design and CGI art creation (helping designers visualize, test, and develop concepts quicker), as well as manufacturing.
Image processing. The applications here include super-resolution, image modification/enhancement, synthetic object generation, attribute manipulation, and component transformation.
Healthcare. The models can help reduce the time and cost of early diagnosis while increasing its speed. In addition, they can significantly augment existing datasets by performing guided image synthesis, image-to-image translation, and upscaling.
Biology. Stable Diffusion can assist biologists in identifying and creating novel and valuable protein sequences optimized for specific properties. The networks’ properties also make them great for biological data imaging, specifically for high-resolution cell microscopy imaging and morphological profiling.
Remote sensing. SD can generate high-quality and high-resolution sensing, and satellite images. The networks’ ability to consistently output stable multispectral satellite images might have huge implications for remote sensing image creation, super-resolution, pan-sharpening, haze and cloud removal, and image restoration.
Marketing. Stable Diffusion networks can create novel designs for promotional materials, logos, and content illustrations. These networks can quickly produce high-resolution and photo-realistic images that meet specific design requirements, and output a wide range of shapes, colors, sizes, and styles. In addition, the algorithms enable augmenting, resizing, and upscaling existing materials, so they can potentially improve the effectiveness of marketing campaigns.
Diffusion models are insanely popular right now. Their unique image-formation process, consisting of the sequential application of denoising autoencoders, achieves stable state-of-the-art synthetic results on images and other data types. Stable Diffusion, which takes image processing out of the pixel space and moves it into the reduced latent space, enables us to achieve high-quality results while running the networks on our laptops. And, the latest text-to-video networks extend pre-trained SD networks with advanced video processing capabilities.
Although the models are new, there are already many companies that have figured out how to use them to their advantage. If you would like to learn how diffusion networks can benefit your organization, contact our experts now.

Explore a strategy that shows you how to choose a cloud platform for your AI goals. Use Avenga’s Cloud Companion to speed up your decision-making.

Avenga and Qinshift are excited to share the news of Aaron Wall’s appointment as Vice President of Business Development in the US and North America.

Take an in-depth look at some of the most promising asset management trends. These probably determine the future of asset management.

Read the article to learn about the latest trends in the media and entertainment industry of 2025 and beyond.
Avenga announces its partnership with Revvo becoming even closer to its UK-based clients.

Avenga and Qinshift are thrilled to announce the appointment of James Lilley – an experienced IT visionary – as Director of Business Development in the US and North America.

Learn why Avenga was named by Techreviewer as one of the top AI development companies in 2024.

See for yourself how enterprise AI transforms banking and finance. Learn about its benefits, challenges, and strategies for successful adoption.
* US and Canada, exceptions apply
Ready to innovate your business?
We are! Let’s kick-off our journey to success!