


AI in banking: from data to revenue
Watch our free webinar, “AI in Banking: From Data to Revenue,” to explore how AI is transforming the BFSI industry.

It so happens that the topic of our article lies directly at the intersection between two of the most hyping trends of the modern digital world: Machine Learning/AI and Privacy.
On the one hand, Machine Learning (ML) is already at the heart of the magic of today’s high-tech products, powering speech recognition services (e.g., Apple’s Siri), ranking our web search results, and recommending videos on Netflix or YouTube, as well as approving bank loans, helping to drive cars, detecting cancer and much more. Machine Learning has become a synonym for innovation. Thus, if a company wants to stay competitive in the market, it has only one option: ride this wave of AI or even an AI tsunami, or be washed out by it.

On the other hand, Machine Learning requires tons of data to learn on. At first glance, it doesn’t sound like a problem to acquire some data in the modern world where even a toaster in the kitchen is generating data. But, if you switch from toasters to people, you’ll find the object much more sensitive: most of the data related to people is considered private. Even the faces of people you see in the streets can’t be photographed and used without their permission.
This affects Data Scientists when they want to use people’s speech to improve speech recognition algorithms or their faces to develop face recognition algorithms, and Data Scientists, of course, are thankful for car camera recordings that help make safer cars, and so on.
Especially sensitive and highly regulated in the data privacy area is the healthcare industry.
The situation looks pretty stable and clear: we are respecting the users’ privacy and asking consent for personal data usage before including it into training data sets (in the case of healthcare this consent should be asked for at the end of each and every case) and there is no room for maneuver.
But let’s imagine for a second that we can do ML on private data while keeping it hidden. This would solve the problem, and it doesn’t even really sound like magic if we remember that scientists invented a way to play poker by phone. The actual process for doing this is called Federated Learning (FL).
Before looking under the hood of FL, let’s try to understand what it potentially gives us, how we can use it and who are the users.
The best point to start with is by comparing traditional Machine Learning and Federated Learning.
By the way, if you would like to refresh your knowledge on Machine Learning here is a great article from Olena Domanska, a PhD and Head of Avenga’s Data Science Competency. It will be also useful for the “under the hood” part of our article since it covers both the basics and mechanics of ML.
In the standard ML setup, data is usually collected from one or multiple clients and stored in a central storage.
A Data Scientist has access to the data in the storage for doing ML.
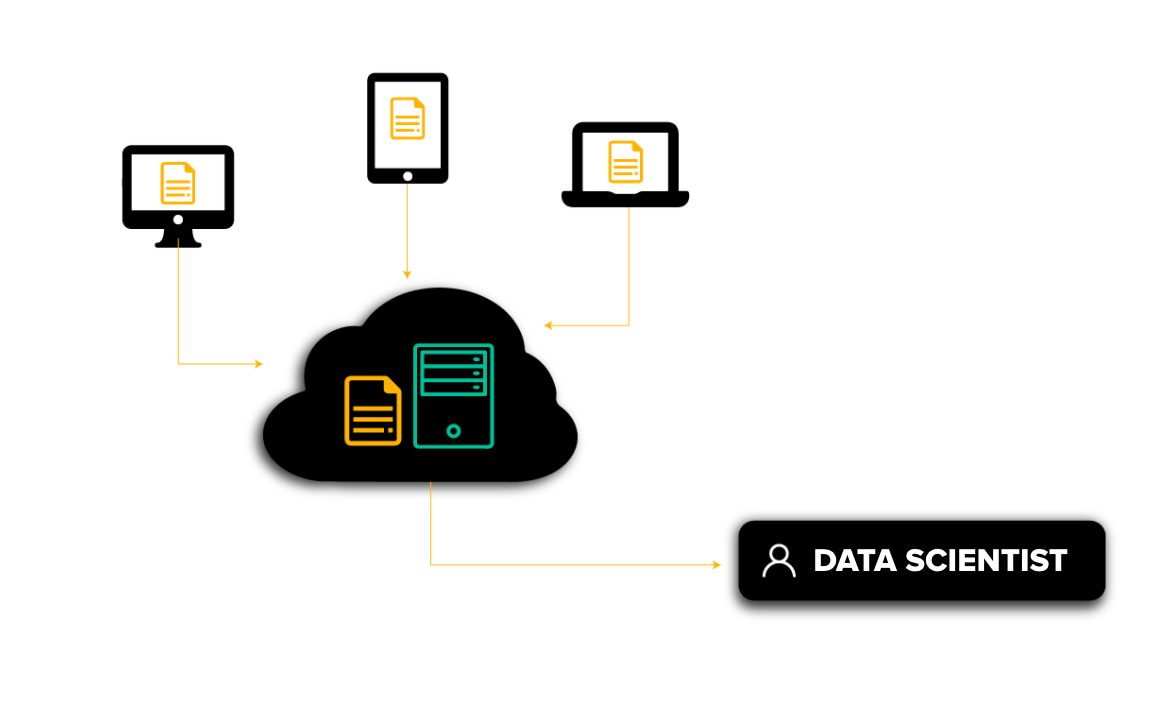

Opting for a Federated Learning (FL) setup, we can overcome these 4 constraints.
First of all, forget about raw data in the central storage. All data should be stored locally, thus “traditional” ML should happen on local devices. (Except testing data and/or public data for a base model, if any)
Now let’s take a look at the possible set-ups of federated learning:
To understand the mechanics of creating this common resulting model, we will examine an example of model-centric, cross-silo, centralized, horizontal FL.
Let’s assume we have several healthcare research groups that decide to implement a common lung pneumothorax detection ML model together without exposing the data owned by the separate hospitals they are working in.
Usually, data scientists would start from some base model that was built on open data. Organizations start to use the model and improve it in their local Machine Learning environments. The improvement process is coordinated by the server and parameters of NN that are constantly circulating among the server and clients while the raw data stays untouched.
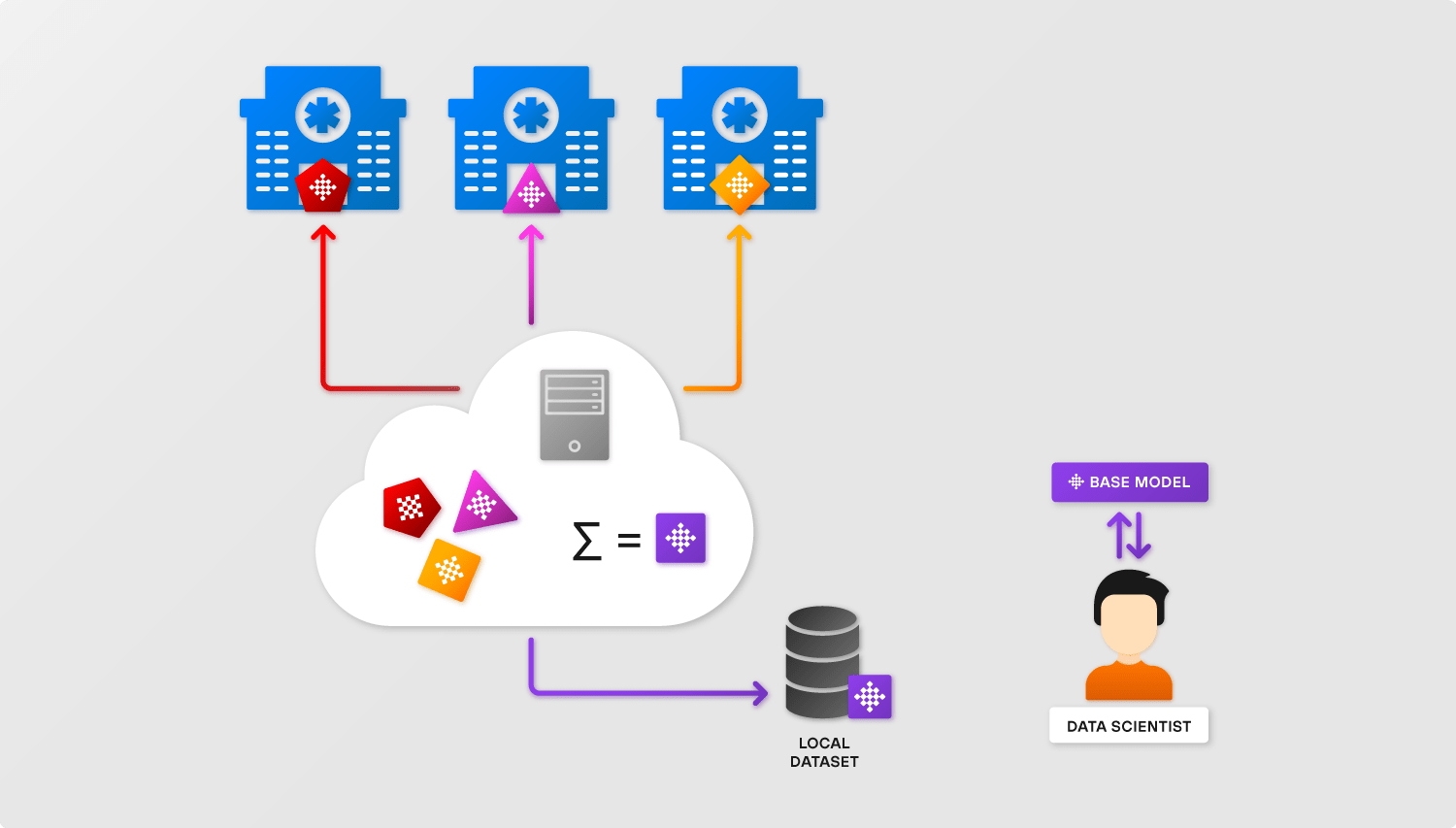
As a result, we have an aggregated model in the server incorporating data insights from each client without the ability to reconstruct the raw data (the ideal case). Data scientists would be testing and propagating this new model to the clients.
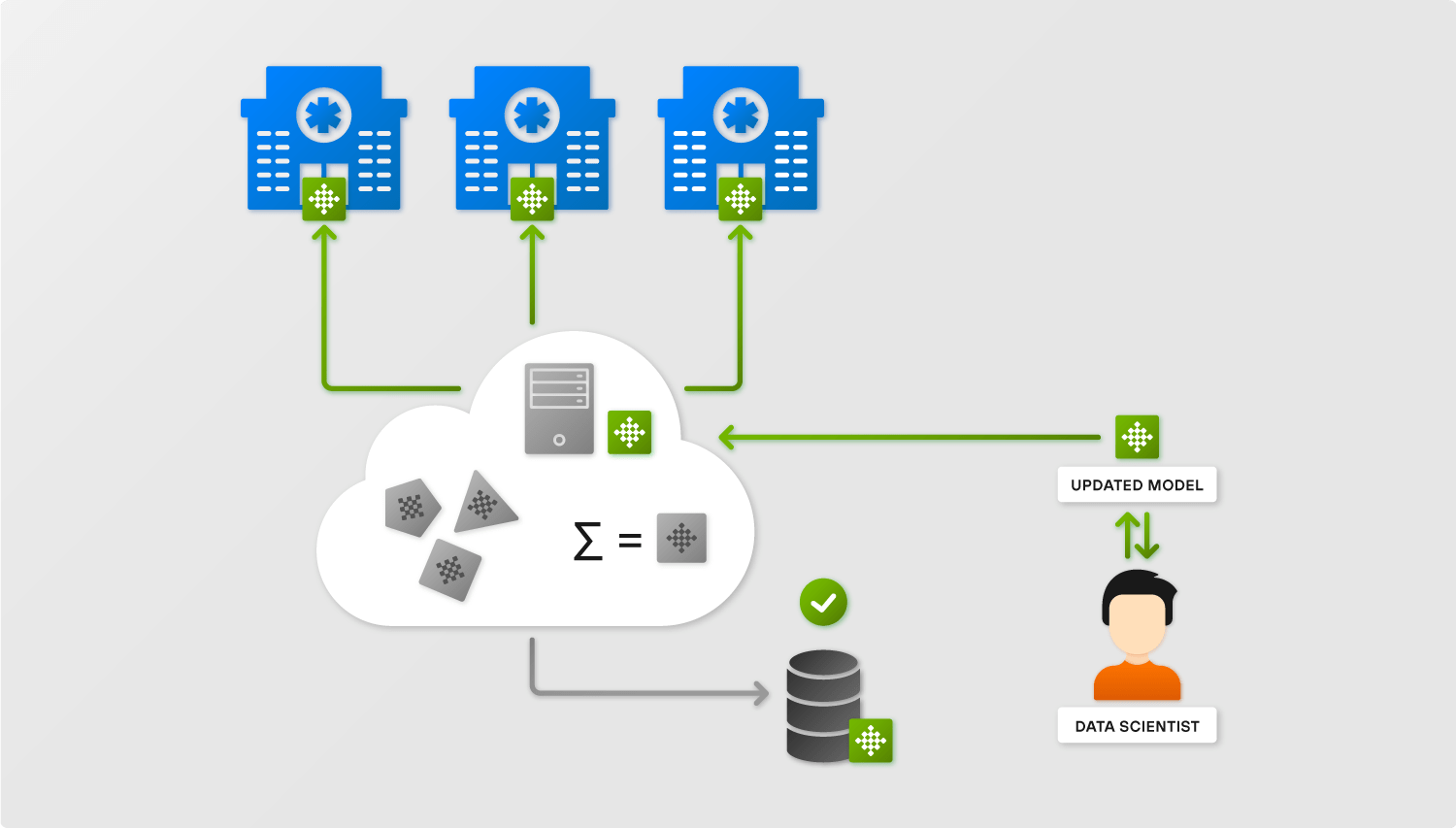
Secure Aggregation for Federated Learning
It looks like we have a perfect solution – we simply aggregate gradients from local models and end up with a better model that avoids raw data exposure. But things, as usual, are more complicated. Such a simple Federated learning setup is vulnerable to reconstruction attacks where raw data can be reconstructed from gradients.
So let’s use some “poker by phone” magic, but officially called Secure Multiparty Computations. Here are 3 levels of one of the possible protocols that we would like to explain (cutting some edges for simplicity):
1. Before sending gradients to the server, users mask the gradients by adding symmetric random perturbations that they’ve obtained for each user by a private channel. Therefore, after summarizing the masked gradients, the server receives the true gradient sum since the symmetric perturbations will eliminate each other.
The weak points here are:
– The private communication channel among users
– Dropped users: each dropped user takes away his/her part of the symmetric perturbation and the math no longer works on the server.
2. The second level introduces public-private key cryptography to enable communication through the server and to make users aware of who is who
Communication with the server has more rounds now:
It looks almost perfect, except for the fact that we exposed the gradients of the users that were dropped on the last round and a potentially malicious server could request shares for those particular users and reconstruct their gradients.
3. To force the server to be honest, we can mask each gradient not only by perturbations, but also by adding a uniform random number, which is also shared by Shamir’s schema. And, we establish the rule that on the last round of dropped users, the surviving ones cannot share both perturbations and a random number for the same user. So, the gradients are always masked, either with random number or perturbations, and the server can do nothing but ask for a random number for any surviving users and perturbations for the dropped users (leaving their random numbers as uniform noise affecting the gradient).
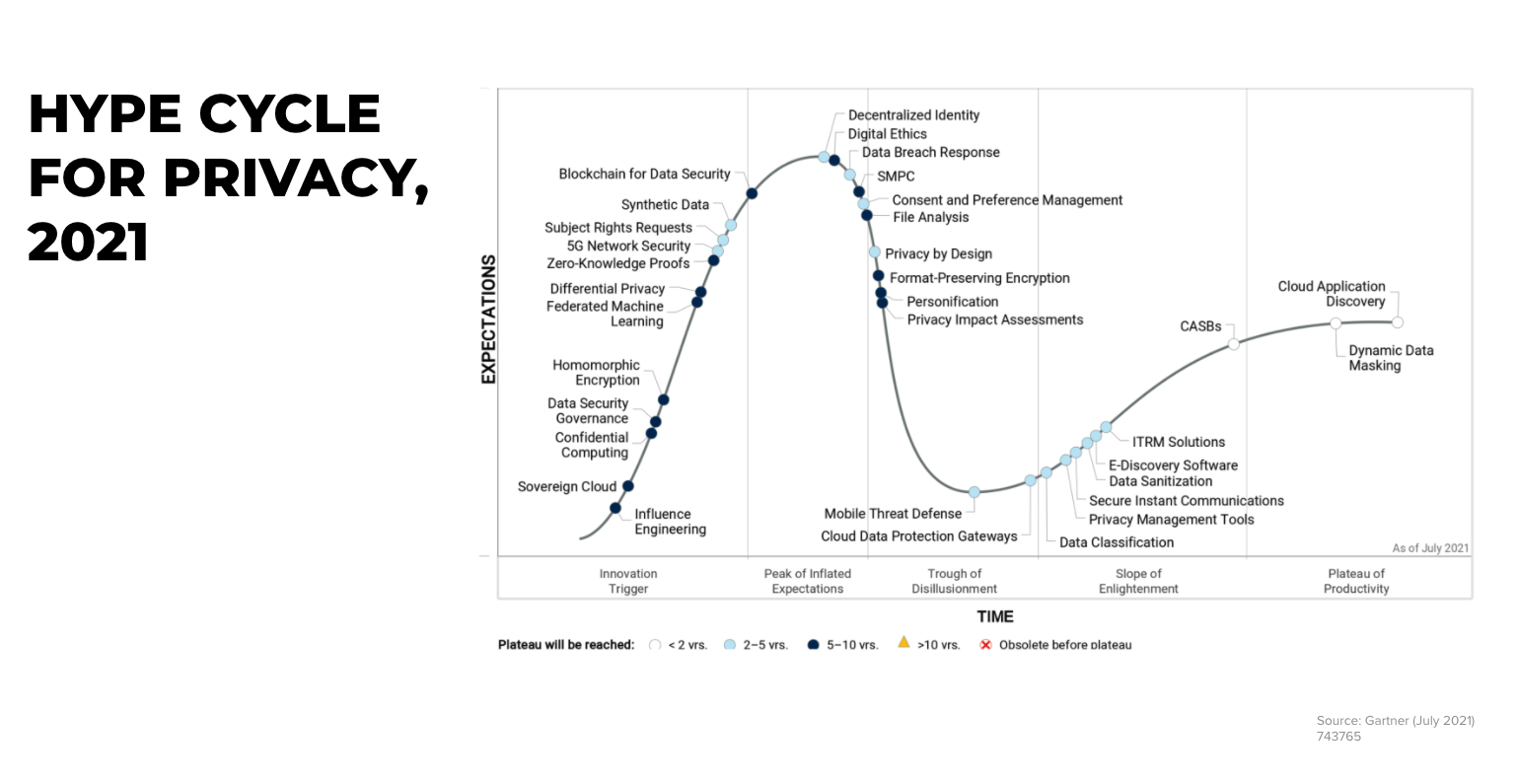
According to Gartner’s Hype curve for Privacy, Federated Learning is now rising far from the peak, so the market is currently experiencing significant activity in this area. Lots of open source FL platforms and lots of start-ups founded by people from Healthcare, Finance and other industries who have big hopes in FL.
We did not aim at the general market overview with our research, but rather decided to compare 3 opensource FL platforms and then used the winner to implement the Computer Vision task of detecting lung pneumothorax. The legend is that we have two organizations keeping their data private and we wanted to build an aggregated model better than each of them could build separately.
The task at hand is the classification of the SIIM-ACR Pneumothorax Competition hosted on the Kaggle platform. The competition is concerned with classifying images into cases with and without a pneumothorax, i.e., collapsed lung. Such a condition can occur from lung disease, chest injury, or for no apparent reason at all.
Usually, a radiologist is responsible for diagnosing a pneumothorax, but as in many other medical conditions, it can be fairly challenging to confirm such a diagnosis. The general idea is that the air enclosure is usually just a mild disturbance in the chest X-ray, and thus, the collapsed lung sometimes can be overlooked. An accurate computer vision model could either interpret the severity of the condition or serve as a second-hand diagnosis for patients.
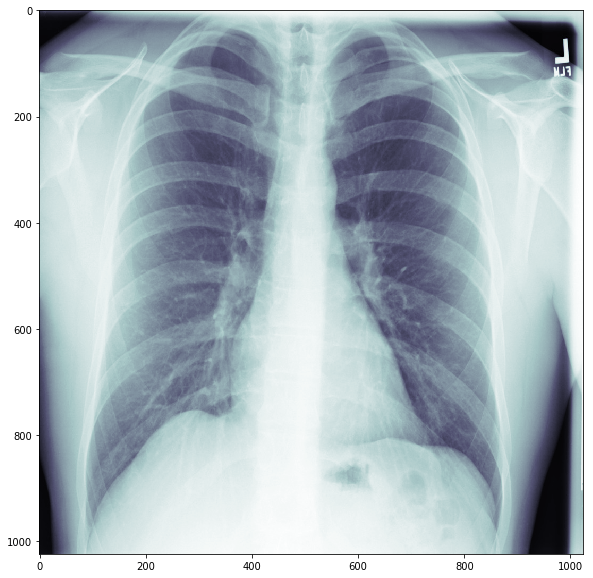
Data for this challenge is being provided by Society for Imaging Informatics in Medicine (SIIM). The dataset contains X-ray images in the resolution of 1024×1024 in a DICOM format. Thisformat provides us with case metadata: the gender and age of the patient and information on the way the image was generated and sampled. A typical lung x-ray looks like this:
In the central images you may see the pneumothorax location:
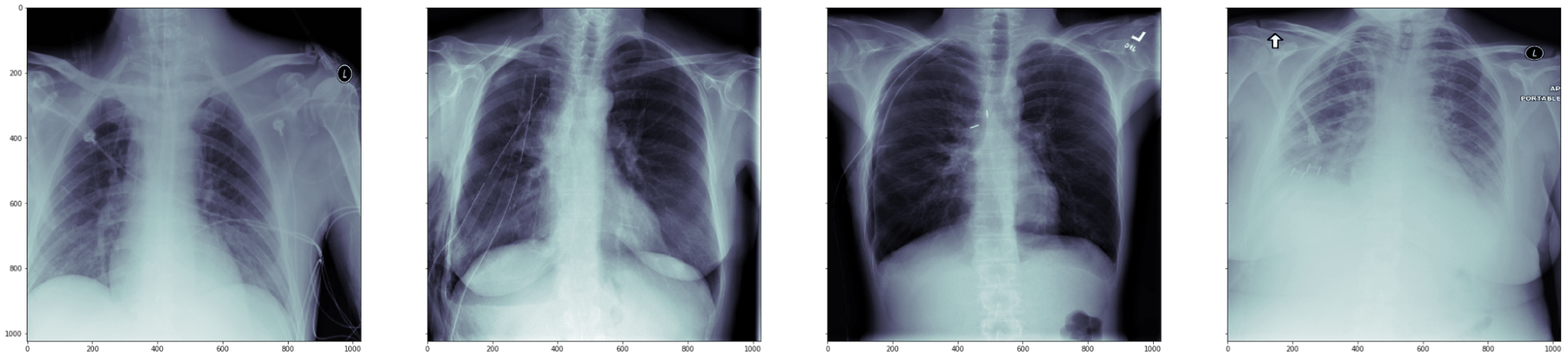
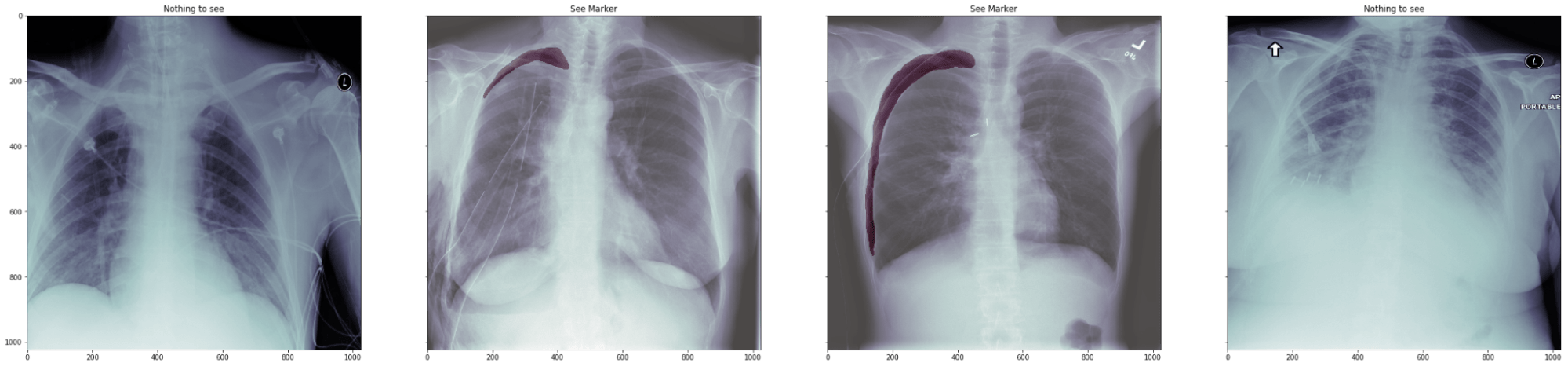
These images were generated in this tutorial.
For training our classification model, we used PyTorch. As a model, we used the ResNet-18 by He et al. We used Focal loss to prevent overfitting during the training and it addressed the imbalance in the data.
Images were heavily augmented with spatial (flip, shift/scale/rotate and crop) and color (gauss noise, CLAHE, sharpen, brightness/contrast, gamma, and median blur) augmentations. Also, images were resized to a 512×512 resolution for efficiency reasons.
To set up the federated learning pipeline, we tested three different frameworks which looked the most promising and had the highest community support: PySyft, FATE and Flower.
PySyft: a library for computing on data that you do not own and cannot see
As its description suggests, PySyft allows any computation on the remote data. Indeed, it supports all the operations available in the PyTorch framework that work on the remote arrays of data that cannot be directly accessed.
The key principle of the framework is that any data derived from the private data is also considered private. This also affects the Machine Learning model, the weights of which are derived from the private data instances. To access the model or any training logs, the Data Scientist has to submit a request, which should be manually processed by someone on the client side. The support for automatic request processing was not available at our specific moment, yet the authors claimed to be working on it right then.
Manual request processing creates two fundamental problems. Firstly, it requires someone to continuously process requests, a so-called Data Administrator. Manual processing also can create delays in the Data Scientist’s work. Another problem is that a human makes a decision on which data to reveal to the Data Scientist. This process is always prone to errors, as the Data Administrators can be tricked relatively easily. As an example, the Data Scientist might make a non-obvious query from which it is possible to reverse the input data. Amore sophisticated approach would be to overfit a model on a single data case and recover the data instance from the weights, which has been proven to be possible.
Implementing the learning pipeline using PySyft is relatively easy, but the framework currently has fundamental problems with privacy presersations. Thus, we decided to test other options.
FATE: An Industrial Grade Federated Learning Framework
Another very promising framework is FATE. It was built using a completely different paradigm compared to PySyft. Instead of allowing any operation on private data and relying on a Data Administrator to not allow data leakages, the framework has a predefined set of learning algorithms, which can be run on the data. Logging, model checkpointing, plotting results and secure communication between different nodes is handled inside the framework. This approach doesn’t allow curious Data Scientists to misappropriate any data.
On the other hand, FATE has a very limited number of supported algorithms. For our problem, we needed at least the support for Deep Learning in general and Convolutional Neural Networks (CNN) in particular. Unfortunately, currently FATE doesn’t support CNN layers and is only limited to Fully-Connected neural networks. This limitation prevented us from using this framework for our task.
Flower: A Friendly Federated Learning Framework
Flower offers a few great features. It is scalable up to 10,000 clients running on many kinds of servers and devices, both mobile or edge. Also, it is compatible with both TF/Keras and PyTorch, or even plain NumPy. All that is needed is to wrap your training pipeline into a simple client class, and you are set to train. Also, communication is well managed and handled by the framework. However, it does not provide capabilities for federated analytics.
To present the compared model performances, we used four training setups:
1. Training without Flower and with a regular fully-supervised classification pipeline.
2. Training without Flower and with a regular fully-supervised classification pipeline within the randomly sampled first half of the data.
3. Training without Flower and with a regular fully-supervised classification pipeline within the second half of the data.
4. Training with a federated learning setup with two clients, each training on its half of the dataset.
We were aiming to predict the pneumothorax in our images in the test set, not seen by the model during the training process. Therefore, the results presented refer to performance on the test subset of the data. We used the F1 score as a metric for an accurate representation of classification performance on imbalanced data.
| Setup | Test set performance (F1-score) |
| Standard ML, 100% of train data | 74.67% |
| Standard ML, 50% of train data (#1) | 68.83% |
| Standard ML, 50% of train data (#2) | 66.21% |
| Federated learning, 100% of train data | 72.93% |
From these results, we can conclude that the FL setup has only minor losses in performance compared to a regular setup. However, there is an obvious advantage when compared to training on half of the dataset. Therefore, it is a good argument to encourage sharing data safely with a federated learning setup to achieve better model performance.
Federated Learning approaches problems that, when solved, will revolutionize our digital civilization. Individuals will be able to help the community in different scales without losing privacy across many areas, starting from Healthcare on up to Autonomous cars. Organizations will be able to improve their industry without compromising their clients’ private data, disrupting corporate know-hows and losing their competitive advantage.
However, to make this happen, Privacy Management in general and Federated Learning in particular should fight through some typical ‘childhood’ problems and find legal support from corporations and governments.

Watch our free webinar, “AI in Banking: From Data to Revenue,” to explore how AI is transforming the BFSI industry.

Explore a strategy that shows you how to choose a cloud platform for your AI goals. Use Avenga’s Cloud Companion to speed up your decision-making.

Avenga and Qinshift are excited to share the news of Aaron Wall’s appointment as Vice President of Business Development in the US and North America.

Take an in-depth look at some of the most promising asset management trends. These probably determine the future of asset management.

Read the article to learn about the latest trends in the media and entertainment industry of 2025 and beyond.
Avenga announces its partnership with Revvo becoming even closer to its UK-based clients.

Avenga and Qinshift are thrilled to announce the appointment of James Lilley – an experienced IT visionary – as Director of Business Development in the US and North America.

Learn why Avenga was named by Techreviewer as one of the top AI development companies in 2024.
* US and Canada, exceptions apply
Ready to innovate your business?
We are! Let’s kick-off our journey to success!