

AI in banking: from data to revenue
Watch our free webinar, “AI in Banking: From Data to Revenue,” to explore how AI is transforming the BFSI industry.

Here, at Avenga, we are always looking for something interesting to discover, as well as to learn new things every day. To effectively moderate such activities – but, obviously, not solely because of this – we run an R&D stream. In pre-quarantine 2019, we had some really strong folks on the bench in the Java department (which doesn’t happen often) and we didn’t think twice about what to do. At that time, we wanted to focus and deepen our hands-on experience with Reactive Programming enhanced with some kind of high-load.
We also strongly believe that if learning is not fun, it is not very effective. By coincidence, we were passionately into Dota2 at that time and we played it almost every day.
Almost immediately we summed up 2 and 2: why not do something – we dunno what – with Dota? Back then, creating something capable of ingesting tons of in-game data sounded quite intriguing.
But, choosing Dota2 was not simply because we were into it. There was a lot of pragmatism and business value-added involved.
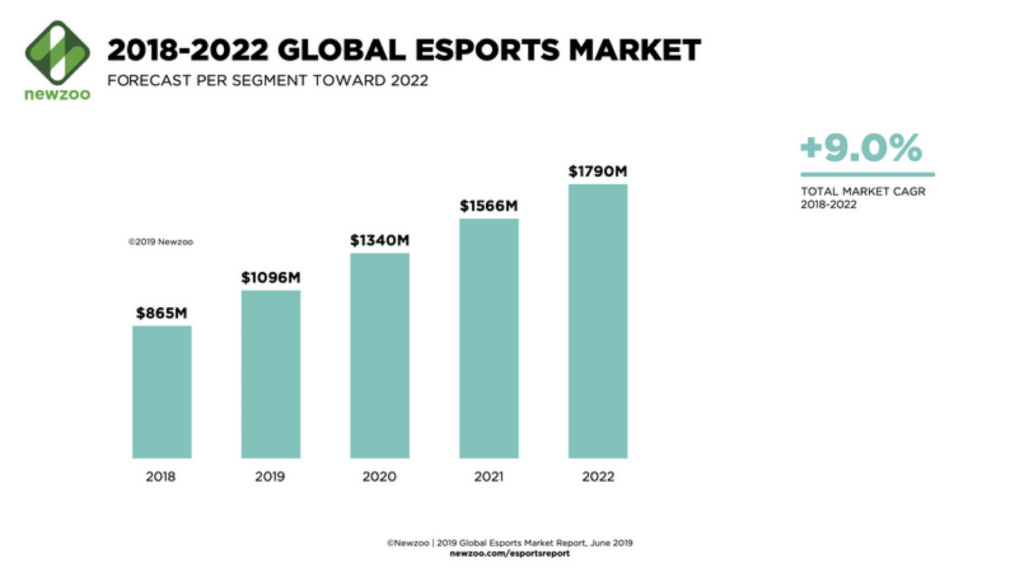
Playing video games is not exclusively a business for dev studios or publishers anymore. The eSport market is growing quite rapidly and during the pandemic it is in better shape than regular sports.
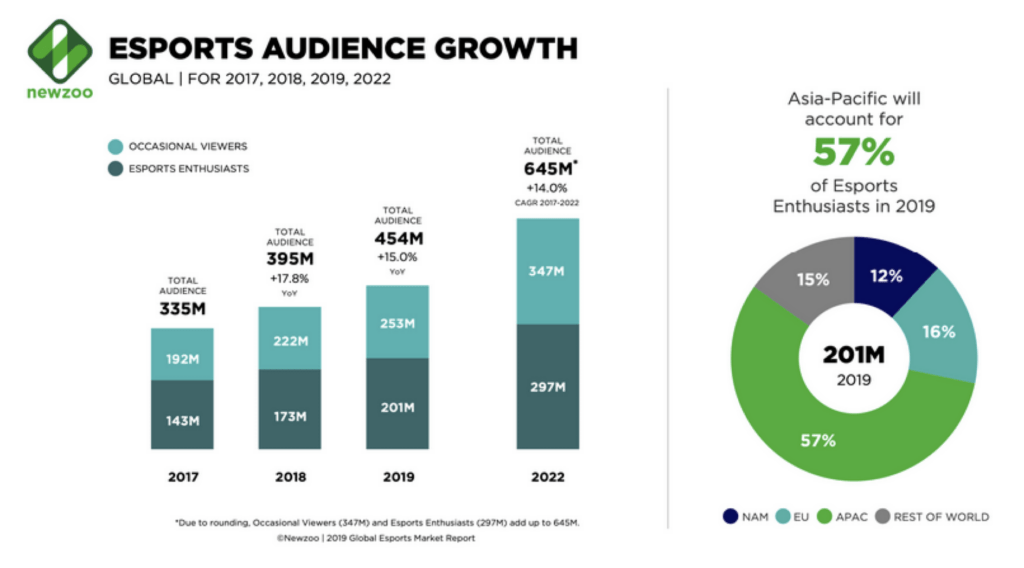
It is worth mentioning that today many old-school sports manufacturers are already paying close attention to this domain; like Puma, for example.
OK, you might argue there are a lot of eSport disciplines out there. Why Dota2?
Well, first of all, because we have significant knowledge about how things are done within Dota2.
Secondly, Dota2 is the biggest eSport discipline in terms of earnings right now.
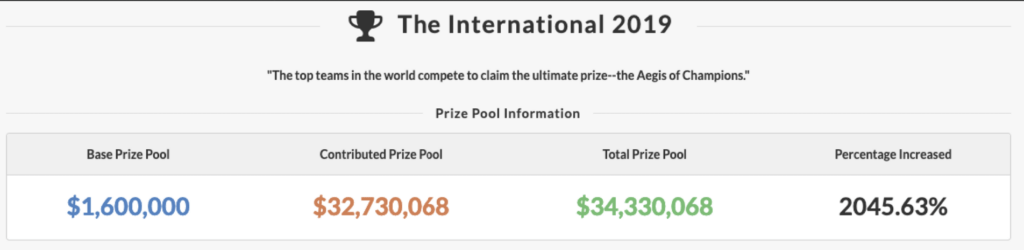
Also, Dota2 has a lot of data.
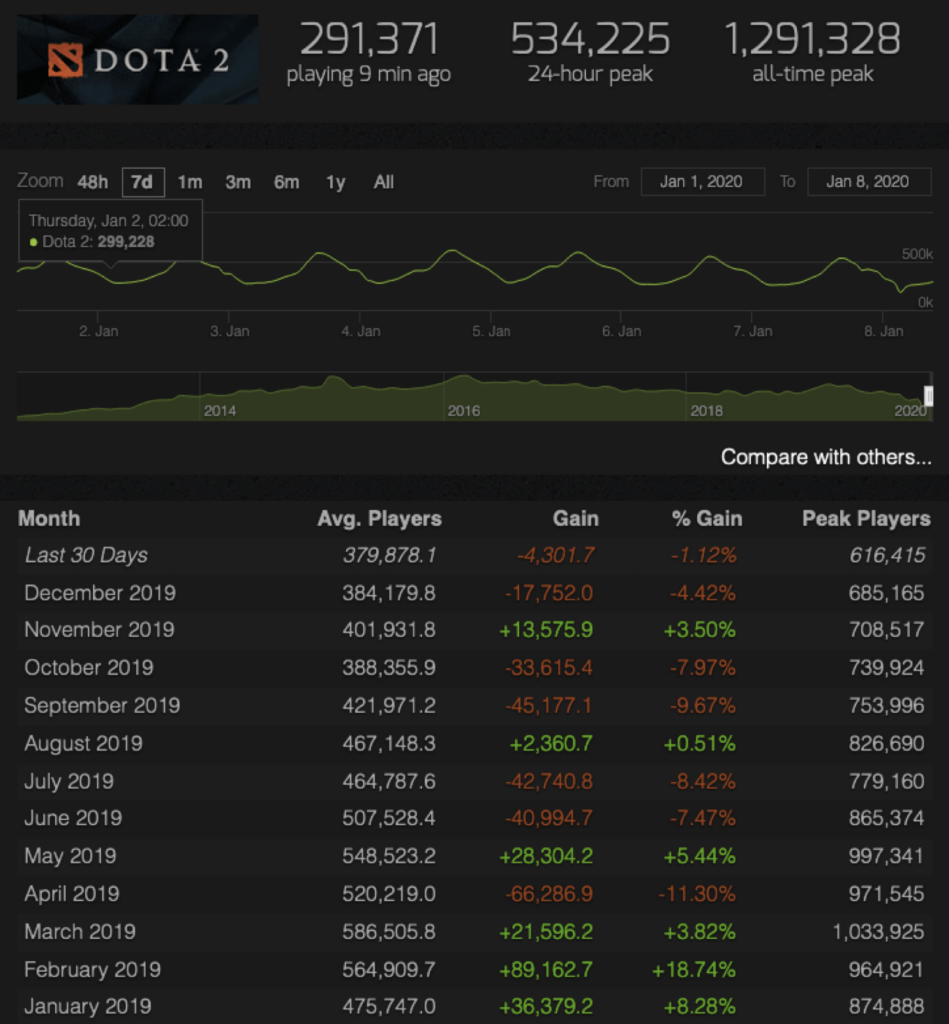
We mean a HELL OF AN AMOUNT OF DATA.

OK, what do we have then? Several skilled Java engineers who played Dota2 almost every day, a growing eSport market, and access to R&D’s data scientists and tools. Having said that, why not build an analytic tool around that data? A tool that can detect some anomalies and predict match results?
→ Read on: How to develop an anomaly detection system that shortens claim resolution time by 30%
And, wouldn’t it be nice to be capable of detecting some changes of in-game meta with state-of-the-art ML algorithms? We planned to go live with this before the TI10 (The International).
From that moment, it was a case for the R&D department.
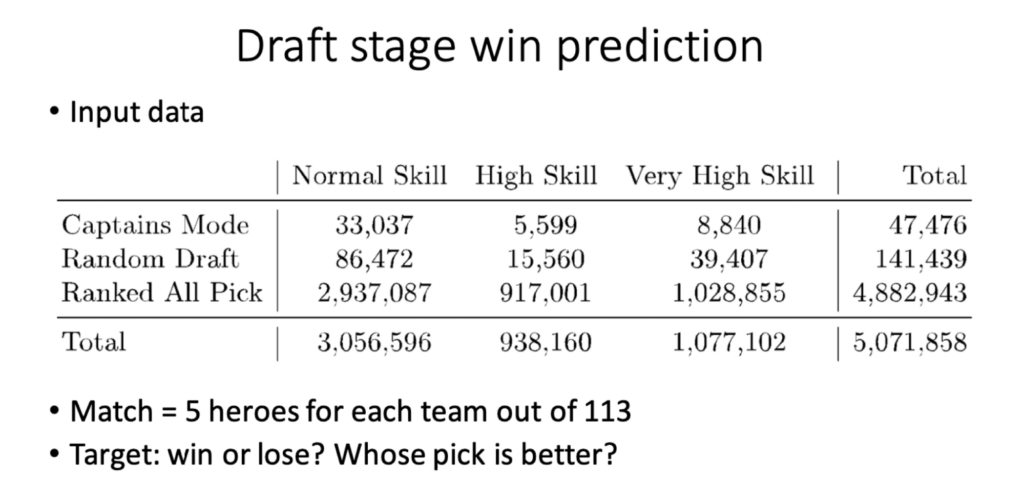
Looks intriguing, doesn’t it?
What could be easier? Let’s build a 3-component system: a Service(1) for calling a Dota2 API (API available through TeamFortress API), and a Service(2) that will aggregate data into a PostgreSQL(3) database.
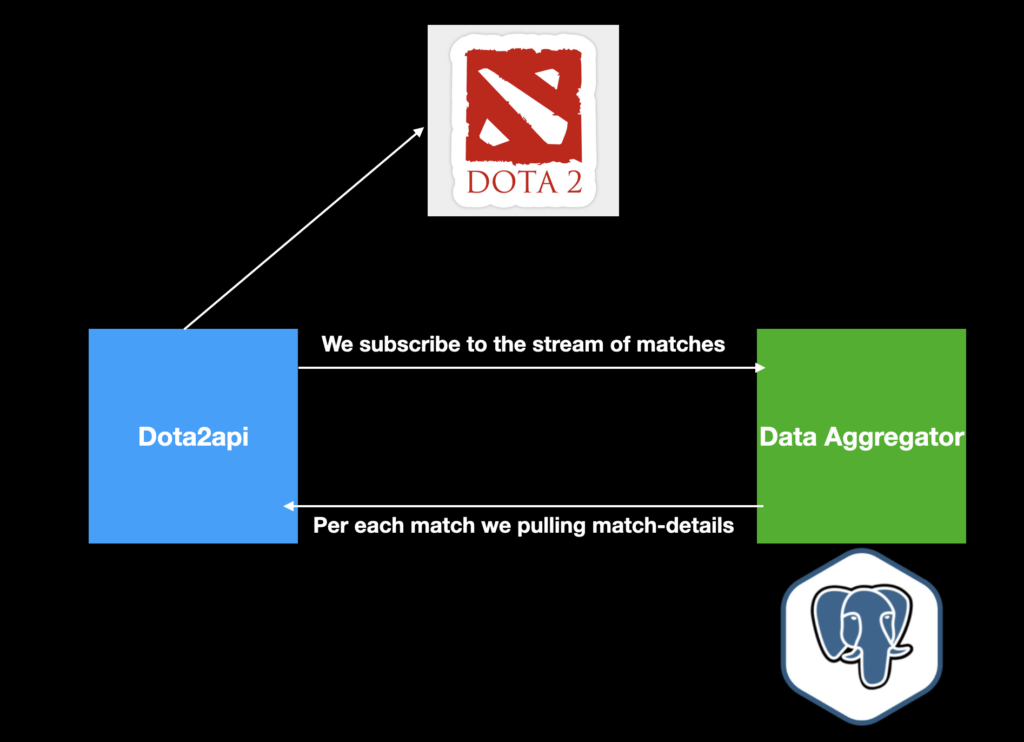
Hold on a second. Don’t we need to add something for the Data Scientists to work with? They can surely work with SQL, but it would be way more efficient to have some pre-aggregated data sets.
So to answer these questions, we decided to complicate things a tiny bit.
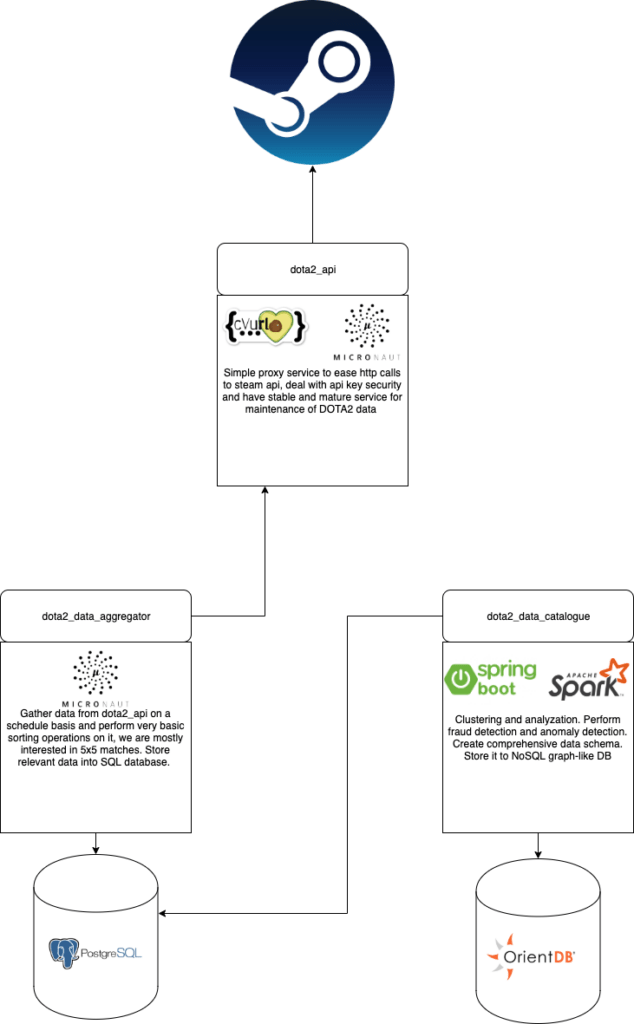
We are all set. However at first sight, it turns out that TeamFortress API didn’t have all the necessary data. Here you can find an example of JSON matches and each of the match details.
What was not OK? First of all, there is incomplete data. Each match in Dota2 generated tons of data that could be analyzed, but only a very small amount of that info was available through the API. Mission-critical data around items, levels, etc. was missing.
Secondly, there was an issue with the quality and quantity of data. If you look carefully through the matches, you’ll find that 85% of them were 1vs1 or some other practice lobby. If you decide to dig deeper, you will find that the remaining “good” matches were also not suitable for providing hints or building a comprehensive analysis of the game, as some of them were one-sided, while in others the players broke their items, they stayed in AFK, or the game was ruined by account buyers or smurf accounts.
Hence, it turns out that we faced 2 major issues: the absence of reasonable data and then data garbage; our approach and architecture couldn’t be answered.
Luckily, it is not just us at Avenga who play Dota2 in our spare time …
The Steam Game Coordinator is a server application within Valve’s game ecosystem (Dota2, CS: GO, Artifact) that matches your account to a game and, well, coordinates your in-game activities. Without it, you cannot be queued for any matches online.
A big shout-out to the SteamKit2 developers! From them, we got a tool that can connect us to the real Steam Network and request data from it on behalf of a real-account user. Originally, it was written in the C++ language and then switched to C#. A weird choice.

Most of the bots use Steam Network APIs for obtaining information about trading cards, workshops, or other information from the Steam Store. Also, SteamKit2 APIs provide the opportunity to trade and execute operations like a regular user from a Steam client. SteamKit2 won’t provide the full functionality of the Steam client, but it’s still possible to write something interesting around the available APIs.
In our case, we were interested in additional information about matches from the Dota2 Game Coordinator and SteamKit2 has such APIs. We used APIs to get information about Dota2 accounts that played in a specific match and details about the Dota2 match.
As Java developers, we wanted to use a fully Java solution and using the C# library wasn’t even an option for us.

There was a Java port in the SteamKit2 project, but it was old and abandoned, so we decided to write our own SteamKit2 port. We called it Aghanim – https://github.com/andyislegend/dota2-aghanim
Let’s describe the technical part a little bit.
To start the communication with Steam Network, we need to fetch a list of the available servers from the Steam Web API. After that, we can establish a connection with Steam Network using one (1) of three (3) available protocols: TCP, UDP, or WebSocket. Upon connection, we need to send a ClientLogon message in the same way we do as a real Steam Client with our account credentials. In response, we will get a ClientLogOnResponse message that lets us understand whether the Steam login is successful or not. If everything is good, we are logged into the Steam Network and can make regular API calls to the Steam servers as the default Steam client that we installed on our PC.
But, this is not enough to communicate with the Steam Game Coordinator. First, we need to send a ClientGamesPlayedWithDataBlob message with the Dota2 application ID (or, basically, any other) in order to notify Steam that we have started playing. Steam then will respond to us with a PlayerClient.NotifyLastPlayedTimes message about the status change. The next part of our greeting ceremony will be sending a k_EMsgGCClientHello message to initiate communication with the Game Coordinator. But, here comes the neat part. The Game Coordinator requires some time to establish communication and we do not have any indication whether it is ready for communication or not. So, we simply send several “Hello messages” and hope we will get a k_EMsgGCClientWelcome message response. After we get our Welcome message, communication with the Game Coordinator is successfully established and we can request Dota2 accounts and match detail information.
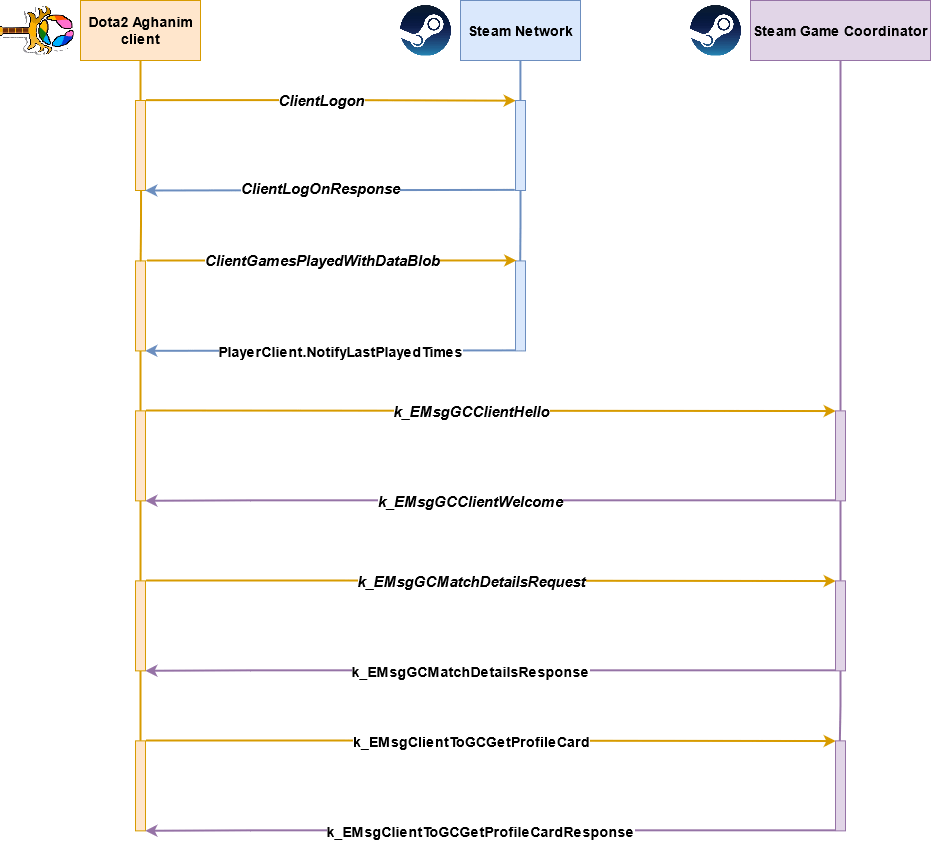
In general, this is just a small piece of the puzzle that is hidden inside the Steam Network communication process. There are a lot of Protobuf messages available in the Steam client. Some of them can be seen below:
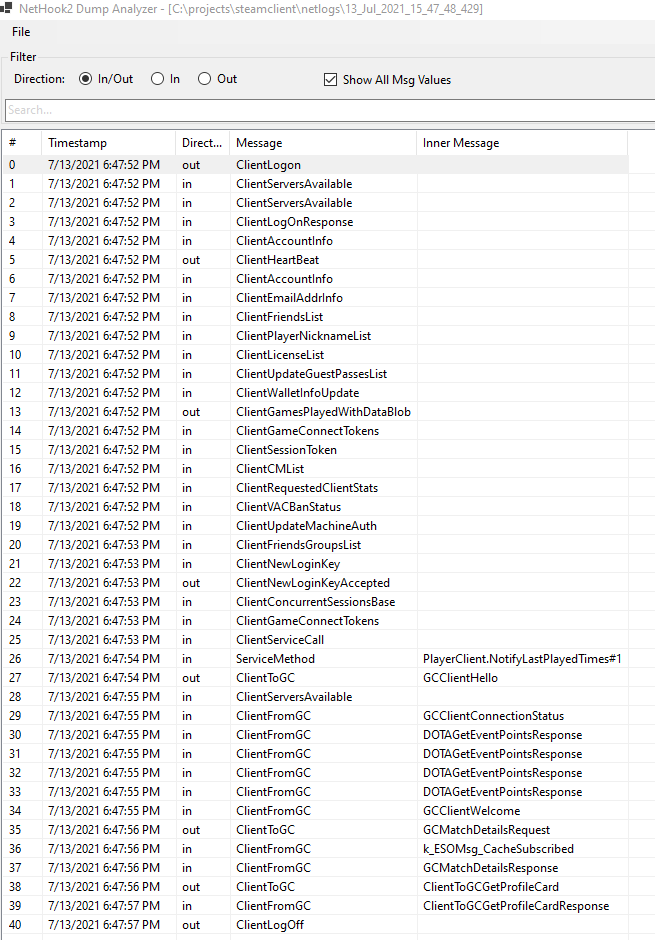
At this point, you might already be wondering: why is it so complicated? And the answer is dead simple – nobody besides Valve knows exactly how Steam Client works internally. We can only mock the behavior of a real Steam Client and, with God’s help, it will work for us. You might say it is not an ideal API for building something on top of and you would be 100% right. But. . .

Boy oh boy, that was just the beginning. While we can easily fetch several thousand account details using the single Steam account, things are not that great with the match details API.
After a series of experiments with several Steam accounts, we finally found out the approximate number of match details that we could fetch using a single Steam account. And, the number was not even close to what we expected to see. It amounted to 200.
When we deployed the first version to our server, we got even worse results. Sometimes a single Steam account would fetch around 200+ matches, but sometimes this number was 0 for a long period of time.
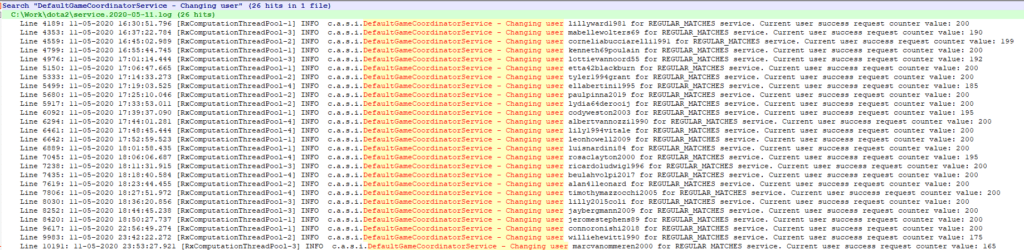
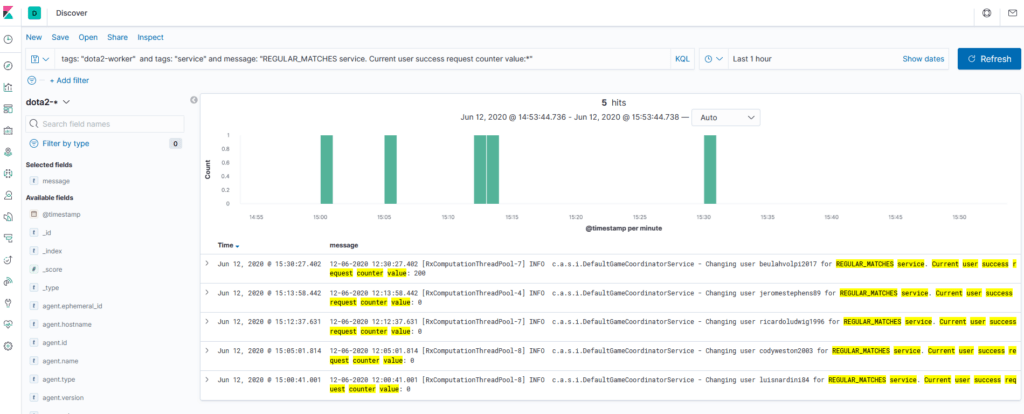
Initially, we were thinking that we were throttling the Game Coordinator servers because we were using a reactive approach with multi-threading. So, we limited processing to a single thread with one Dota2 Aghanim client and added a delay of 100 ms between matchDetails calls. It didn’t fix all of our issues, but at least we had better (or some) control over the behavior of the Dota2 Aghanim client.
The next logical step for us was to create multiple Steam accounts and rotate them as soon as we reached the limit. We didn’t use any hardcoded values, so the logic for rotation was to compare the number of requests we sent and the number of responses we got. Approximately 80% of the requests failed 3 times, which is why we started switching to another Steam account and hibernating the previous Steam account for 24 hours. Why 24 hours? We chose this number based on the ban limit for the Team Fortress API API keys, which we also figured out empirically. By using this retry mechanism + account switch mechanism, it provided us with the possibility to scale our processing capabilities by adding new Steam accounts.
Based on everything described above, we decided to tweak our architecture just a little bit.
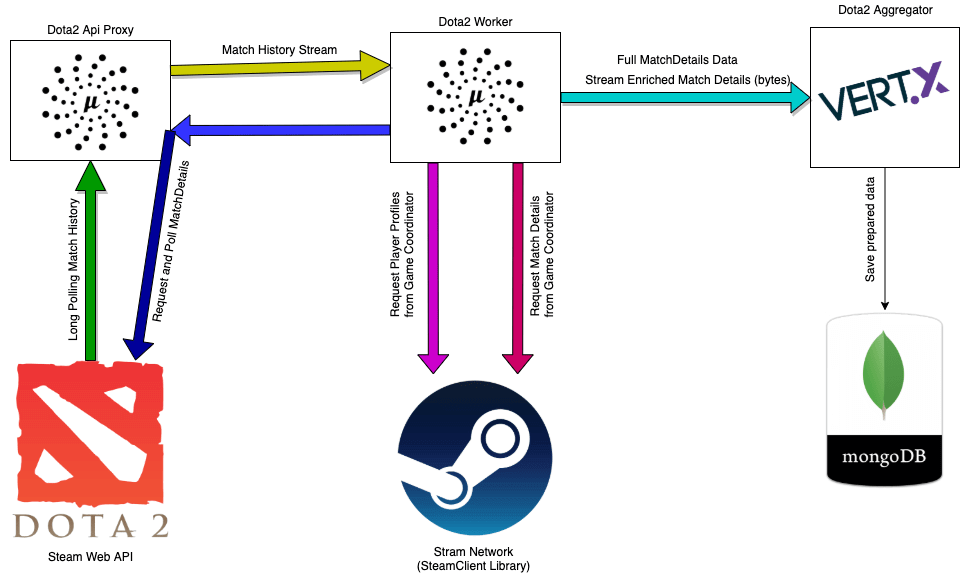
Good architecture is not one that is set in stone at the beginning of system development, but the one that evolves and grows together with the system, answering new challenges the system faces during its lifetime.
With our port to the SteamKit library, we resolved one of the initial issues – completeness of data. Now we had all the desired information about each match that had been played.
But how about the second issue – quality and quantity of data? Partially, it also was resolved by the SteamKit library. Quantity though, is one of the things we couldn’t resolve completely through the end of the project. If you cannot win with pure power, you need to overthink your opponent. So we decided that less is more and tried to focus only on specific matches.
First of all, we only cared about 5vs5 matches that were played in either one of these mods: Ranked All Pick or Ranked Captains Mode. We decided that not having matches in other mods or in an unranked format made very little difference for us due to the lack of team play and lots of experiments, as well as being barely able to represent the current game’s meta (What is meta? Please read https://liquipedia.net/dota2/Metagame). Also, the same rule applies to low-MMR (what is MMR? Please read https://dota2.fandom.com/wiki/Matchmaking_Rating) games; on 2-3k MMR there is NO meta and everyone is playing to the best of their skills & knowledge, but there is no teamplay, no strategies, nor synergies, which is not what we were looking for.
And, as we mentioned at the beginning of this article, Dota2 has an outstanding professional scene, so we decided that it made perfect sense to collect all the professional games we could.
Some of the information was available through Dota-API and was easy to filter, while other information was available through the Game Coordinator. At each step of our data ingestion, we were trying to reduce the number of matches we had to process.
We were confident in our new approach with the Aghanim library and on our test server everything worked! But then, we deployed it to prod…
We used over 45 Steam accounts to collect data via Aghanim.
Below you can find a screenshot with the statistics that we gathered from Game Coordinator interactions via Aghanim during our 3 days of work:
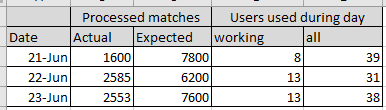
Even from a theoretical perspective, we can process approximately 6,5k match details per day. In reality, this number was always much smaller. We always had problems with the number of matches that the dota2-api service produced (it can produce 10k+ matches per day that are filtered matches based on different sets of rules) and the amount of matches dota2-worker could process.
So naturally, dota2-worker became the bottleneck of our system. Yet again, our system was unable to operate in a stable or predictable way. And again, we needed to be flexible and creative in order to address those issues, often going back to the whiteboard.
Our third version of the system later turned out to be the last one we made during this project. And, our final model that ended up in DB looked like this.
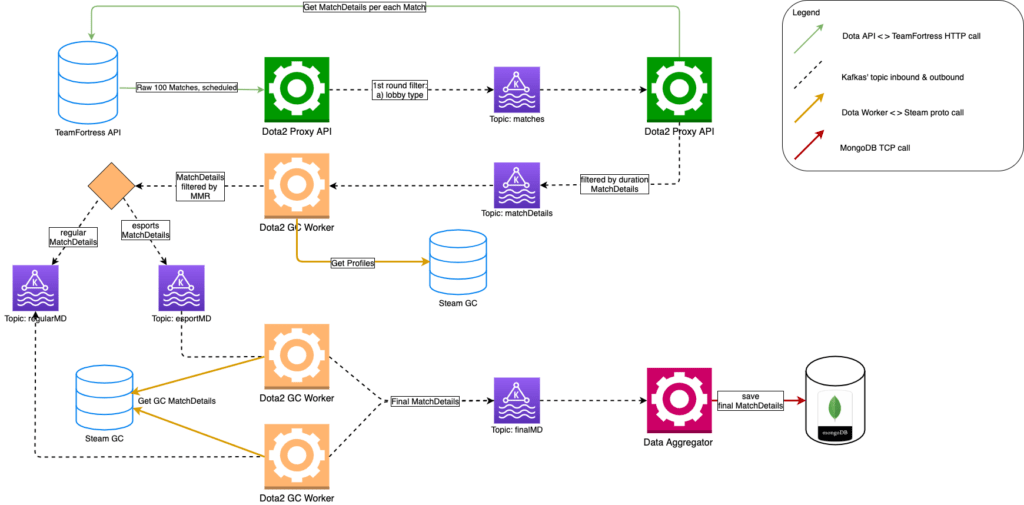
We’ve decided that everything looks better with Kafka. We started to use different topics for regular matches and eSport matches because there were significant differences in numbers. We also used Kafka as a temporary store for matches which could not be proceeded immediately by Aghanim.
Let’s elaborate a smidgen more on how this piece was implemented.
The Dota2-API service tracked the last sequence number of the fetched matches and, based on it, we fetched matches continuously and didn’t care about restarts or failures. As a result, we fell behind with the matches we fetched from Dota2-API and the matchDetails we got from the Game Coordinator. To solve this problem we decided to reset the sequence number of matches each day (each day we started from the newest matches) and this helped. We weren’t able to track all the matches we wanted, but at least we kept on going with fresh data and our database always had actual data.
At the very moment we thought that all the issues had been resolved, we hit another one. Some of our Steam Client accounts stopped producing data . . . at all . . . forever.

One of our assumptions was that the “Steam Game Coordinator most probably has a ban system based on IP address”. Our server had a static IP and a lot of requests from one IP – even from several accounts – could be suspicious. So, we added a proxy connection functionality to our Dota2 Aghanim client. We provided a list of SOCKS v4 proxies and the Dota2 Aghanim client tried to use them to establish an initial connection with the Steam Network using a TCP protocol. We used free proxies available over the internet and in some cases we successfully connected to the Steam Network on the first try, and sometimes we had to change several proxies before Steam allowed us in. We tried our best, but this was the issue we were not able to figure out until the last breath of this project, because sometimes it worked really well, and yet sometimes we had 2-3 Steam accounts processing 200 matches and all the others constantly returned 0 to us.
The biggest issue with solving this problem was that the Steam Game Coordinator has one tricky behavior. In cases where it works, you will get your response back, but if it doesn’t work, you won’t receive any response at all, not even an error. Nothing =). During the development of the services and the Dota2 Aghanim client, we made a lot of assumptions based on our best guesses. Each time we tried to check them using a different set of experiments with local Steam accounts. The only possible way to know at least something about the system’s current status was to log everything. We collected logs using the ELK stack and stored them for one or two weeks.
Our logs contained statistics of the processed matches per Steam account. We also tracked internal logs of the Dota2 Aghanim client. This helped us to understand how the Steam Game Coordinator and the Steam Network worked during longer periods of time. Locally, it was very hard to catch the different cases, of which we had on our production server.
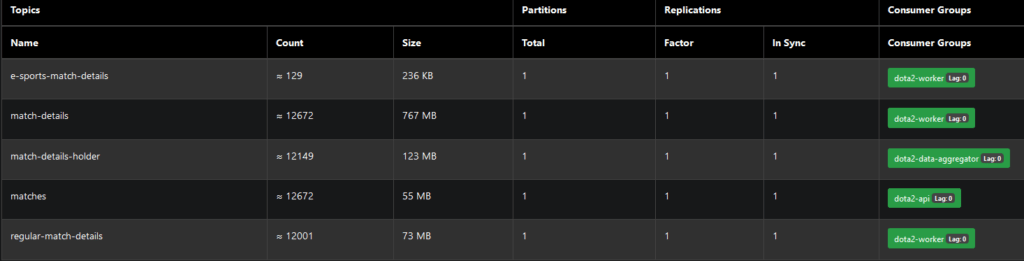
As a result, the final amount of matches we processed with the V3 in our system was around 470k. Sometimes we had the opportunity to see pictures like this (below), but it wasn’t a common thing.
In parallel to the main course, we were also actively looking for options to get even more info about Dota2 matches. Quite an obvious source of such data was match replays; you can have heatmaps, dozens of events that happen every second, etc.
Even though we didn’t use this service in our infrastructure, we were eager to show you how much info you could get from the replays. For an 8-minute 1 vs 1 match, we got 184 868 rows of the formatted JSON.
Sometimes everything that can go wrong goes wrong. Sometimes it’s even your own fault ;). Use those chances to become better, to gain experience and to fight back.
Even though we made great progress towards the stability and productivity of our system, in March 2021 this happened. We don’t know why it affected us, but since then we can barely get any data from the Game Coordinator. For us, it was a dead end.
But, nevertheless, it was a great experience for us. We worked with a domain we love and are very interested in! We gained additional expert knowledge in Vert.X, Kafka, ELK, and docker. We even planned and partially did our migration from Mongo to Cassandra (the amount of data quickly became too large for Mongo to handle) and we totally re-wrote our dota2-worker to Scala and Spark. Plus, our Data Science team had fun running cluster analysis and fraud detection.
→ Explore a real-world case of AI-Powered Fraud Detection for insurtech
Also, we polished up our cVurl library and added all the necessary functionalities for everyday work. This open-source tool is now battle proven and we continue to use it for our commercial projects to this day.
You can always contact us with any questions regarding this project or a similar one. We are ready to help you with your business and initiatives. Regarding our Dota2 project, we believe it is not finished yet and it is just on hold for now.

Watch our free webinar, “AI in Banking: From Data to Revenue,” to explore how AI is transforming the BFSI industry.

Explore a strategy that shows you how to choose a cloud platform for your AI goals. Use Avenga’s Cloud Companion to speed up your decision-making.

Avenga and Qinshift are excited to share the news of Aaron Wall’s appointment as Vice President of Business Development in the US and North America.

Take an in-depth look at some of the most promising asset management trends. These probably determine the future of asset management.

Read the article to learn about the latest trends in the media and entertainment industry of 2025 and beyond.
Avenga announces its partnership with Revvo becoming even closer to its UK-based clients.

Avenga and Qinshift are thrilled to announce the appointment of James Lilley – an experienced IT visionary – as Director of Business Development in the US and North America.

Learn why Avenga was named by Techreviewer as one of the top AI development companies in 2024.
* US and Canada, exceptions apply
Ready to innovate your business?
We are! Let’s kick-off our journey to success!